Pragmatic Patterns Using TMF645 and Its Role in the Order Capture Lifecycle
In the previous article on Customer Order Capture, TMF645 Service Qualification was identified as one of the four core APIs involved in translating customer intent into a valid ProductOrder. Alongside TMF620, TMF679, and TMF622, it occupies a specific and critical position in the architecture — the point at which commercial feasibility meets technical reality.
This article examines TMF645 Service Qualification in depth: what it does, how it fits into the broader order lifecycle, how it relates to other qualification APIs, and what practical patterns emerge when it is implemented correctly in telecom BSS/OSS architectures.
What Is Service Qualification?
Service Qualification answers a specific operational question: can this service actually be delivered to this customer at this location with these technical constraints?
The TM Forum TMF645 Service Qualification Management API provides a standardized interface for checking the technical feasibility of a service request before that request enters the order lifecycle. It sits upstream of order submission and downstream of commercial product selection, acting as a validation gate between intent and commitment.
TMF645 is not about whether a customer is eligible to purchase a product — that is the domain of TMF679 Product Offering Qualification. TMF645 is about whether the underlying infrastructure, network, or platform can actually support the requested service for that specific customer context.
Why Service Qualification Matters
Service Qualification is the difference between selling what you offer and committing to what you can deliver. Without it, the gap between commercial intent and operational execution generates late failures, costly rework, and degraded customer experience.
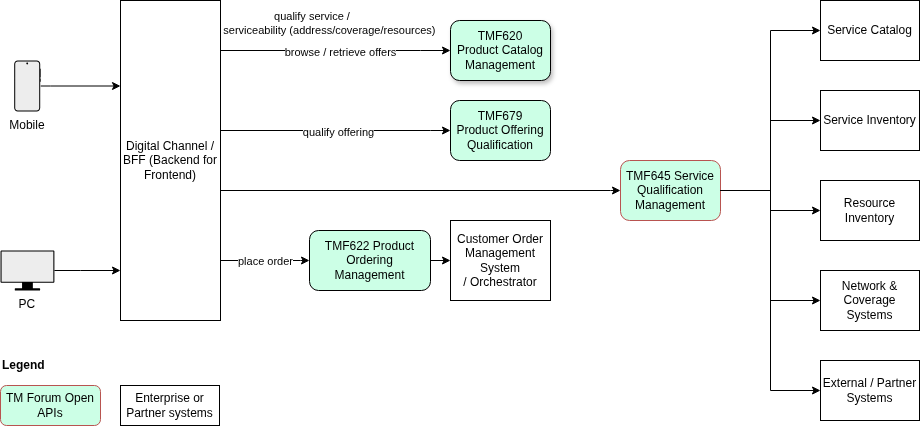
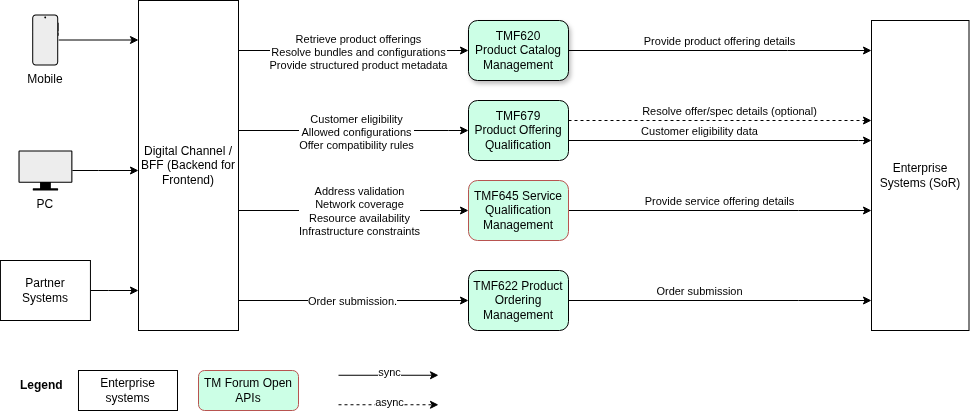
Where TMF645 Fits in the Order Lifecycle
The order capture lifecycle follows a structured progression from product discovery to order submission. TMF645 occupies the technical feasibility stage — after commercial qualification and before ProductOrder creation.
Stage
Primary API
Core Responsibility
Product Discovery
TMF620
Retrieve and browse available product offerings
Commercial Qualification
TMF679
Validate customer eligibility and offer compatibility
Technical Feasibility
TMF645
Verify infrastructure and network delivery capability
Order Submission
TMF622
Capture and submit the standardized ProductOrder
This sequencing is deliberate and architecturally significant. If technical feasibility is checked only during service activation — downstream in the lifecycle — orders that cannot be fulfilled will have already passed through multiple processing stages. The cost of late failure is substantially higher than the cost of early qualification.
By checking technical feasibility through TMF645 before the ProductOrder is submitted, the architecture ensures that only viable orders enter the fulfillment pipeline.
Commercial vs. Technical Qualification: A Critical Distinction
One of the most important architectural separations in the order capture domain is the distinction between commercial qualification and technical qualification. These two validation concerns are often conflated in legacy architectures, producing systems that are difficult to evolve and prone to inconsistency.
TMF679 – Product Offering Qualification
TMF645 – Service Qualification
Is this customer eligible for this offer?
Can the network or infrastructure deliver this service?
Are the selected options compatible with the product?
Is there capacity or coverage at the requested location?
Does the customer’s account support this product?
Are the required resources available and allocatable?
Commercial rules and pricing constraints
Infrastructure, topology, and platform constraints
Catalog-driven validation
Network- and inventory-driven validation
A customer may be fully eligible for a premium broadband offer (TMF679 qualified) but reside at an address outside the fiber coverage area (TMF645 not qualified). These are orthogonal checks that must remain independent to allow each domain to evolve without coupling.
Anti-Pattern: Merged Qualification
Merging commercial and technical qualification into a single validation service is a recurring anti-pattern. It couples the product catalog model to network topology, forces synchronized releases across otherwise independent domains, and makes it impossible to clearly identify why a qualification failed. Keep these concerns separate.
What TMF645 Checks
The scope of a TMF645 qualification check depends on the service type and operational context. Typical checks include:
Check Type
Description
Address and location validation
Confirms the customer’s service address is within the delivery area for the requested service
Network coverage verification
Validates that the required network technology (fiber, cable, mobile, etc.) reaches the specified location
Resource availability
Checks whether required infrastructure resources — ports, bandwidth, spectrum, or capacity — are available
Infrastructure constraints
Identifies topology-specific limitations that may affect service parameters or options
Technology-specific feasibility
For services such as VoIP, IPTV, or mobile, verifies platform availability and compatibility
Third-party or partner dependency checks
For wholesale or shared infrastructure scenarios, queries external qualification systems
The qualification result includes not just a binary qualified or not-qualified outcome, but structured detail about the constraints encountered, the alternatives available, and any parameters that must be adjusted before order submission.
TMF645 API Structure
The TMF645 API supports both synchronous and asynchronous qualification patterns, reflecting the reality that some qualification checks can be resolved immediately while others require queries to external or slow systems.
Core Resources
Resource
Purpose
ServiceQualification
The primary qualification request and result object
ServiceQualificationItem
Represents a single service within a multi-service qualification request
QualificationResult
The outcome per qualification item: qualified, notQualified, or partiallyQualified
AlternateServiceProposal
Proposed alternative configurations when the original request cannot be qualified as submitted
ServiceabilityDate
Earliest date on which the service can be delivered if not immediately available
Qualification States
A qualification request progresses through a defined lifecycle:
State
Meaning
Caller Response
acknowledged
Request received and accepted for processing
Retain qualification ID; await next state
inProgress
Qualification checks are executing
Continue monitoring via polling or event
done
Qualification completed with a result
Process result and proceed or adjust
terminatedWithError
Qualification could not be completed
Evaluate error and retry or escalate
Synchronous vs. Asynchronous Execution
TMF645 supports both execution patterns. The choice between them is not arbitrary — it should reflect the operational characteristics of the underlying qualification systems.
Synchronous Qualification
Asynchronous Qualification
Result returned in same API call response
Result delivered via event callback or polling
Appropriate when all checks are local and fast
Required when external systems or slow lookups are involved
Simpler caller implementation
More complex state management required by caller
Fragile if any downstream system is slow
Resilient to variable response times
Suitable for simple address lookups
Required for partner or wholesale qualification flows
Design Recommendation
Architectural Recommendation: Even when synchronous qualification is technically feasible, designing the caller (typically the BFF or order capture service) to handle asynchronous results makes the integration more resilient. A synchronous qualification that becomes slower over time due to infrastructure growth should not require a re-architecture of the calling layer.
Qualification in the BFF and Channel Layer
In a well-structured order capture architecture, the BFF (Backend-for-Frontend) orchestrates qualification calls on behalf of the digital channel. This keeps the frontend free from direct dependency on TMF APIs while maintaining a clean separation between engagement logic and domain validation.
The BFF is responsible for:
Aggregating product selection, customer context, and location data into a qualification request
Calling TMF679 for commercial qualification and TMF645 for technical qualification
Presenting qualification results to the frontend in a channel-appropriate format
Blocking order submission if qualification has not succeeded
Surfacing alternative proposals from TMF645 if the original request cannot be qualified
The BFF should not implement qualification logic itself. Its role is orchestration and translation — not validation. Qualification rules live behind the TMF645 interface, inside the domain that owns the qualification logic.
Anti-Pattern: Qualification in the Channel
A common mistake is implementing address validation or coverage checks inside the BFF or frontend layer. This creates duplicated logic, inconsistencies between channels, and tight coupling to infrastructure data that changes independently of digital channel releases. Qualification logic belongs behind TMF APIs.
Handling Qualification Results
The outcome of a TMF645 qualification is not always a simple pass or fail. Three result types must be handled explicitly:
1. Qualified
The service can be delivered as requested. The qualification result may include additional information — such as confirmed delivery dates, available service parameters, or resource identifiers — that should be carried forward into the ProductOrder payload.
2. Not Qualified
The service cannot be delivered as requested. The result should include structured detail on the reason for disqualification: coverage boundary, resource unavailability, platform incompatibility, or infrastructure constraint. This information should be surfaced to the customer clearly, with appropriate next steps.
In some architectures, a not-qualified result triggers a waitlist or future-date qualification flow, where the system tracks the customer’s intent and notifies them when qualification conditions change.
3. Partially Qualified or Alternative Proposed
TMF645 supports the return of alternative service proposals when the requested configuration cannot be qualified but a modified version can. Alternatives may include:
A lower bandwidth tier where the full requested speed is not available
A different access technology (e.g., FTTC instead of FTTP)
A future delivery date when current resources are temporarily exhausted
A modified service area or endpoint if the exact address has limited coverage
Alternative proposals must be presented to the customer as genuine choices, not silent fallbacks. The channel layer must handle these gracefully and allow the customer to accept, reject, or modify their selection before proceeding.
Relationship to Order Submission via TMF622
The output of a successful TMF645 qualification is not discarded — it informs the structure and content of the ProductOrder submitted through TMF622. Key qualification data that flows into the order includes:
Qualification Output
Role in TMF622 ProductOrder
Qualification ID
Carried as a correlation reference in the ProductOrder for traceability
Confirmed service parameters
Used to populate the requested characteristics of the order item
Resource identifiers
Referenced in the order to ensure the correct infrastructure is reserved
Delivery date commitment
Reflected in the requested start date of the order
Alternative proposal reference
Included if the customer accepted an alternative configuration
This linkage between qualification and order is architecturally important. It ensures that the ProductOrder reflects not just what the customer wants, but what the network has confirmed it can deliver. Orders that do not carry qualification context force downstream systems to re-check feasibility, introducing redundancy, delay, and potential inconsistency.
Design Principle
Design Principle: The qualification reference should be treated as a first-class attribute of the ProductOrder, not an optional annotation. Downstream decomposition and service activation systems rely on this reference to skip redundant feasibility checks and proceed directly to fulfillment.
Caching, Validity, and Qualification Windows
A qualification result is not indefinitely valid. Infrastructure conditions, resource availability, and coverage boundaries can change. TMF645 results should carry an explicit validity window, after which the qualification must be refreshed before order submission.
Common validity patterns include:
Pattern
Description
Time-bounded validity
Qualification result is valid for a defined period (e.g., 24–72 hours) before expiry
Event-invalidated qualification
Qualification is invalidated if specific network events occur (maintenance, topology changes)
Commitment-based holding
For high-demand resources, qualification results may optionally reserve capacity for a defined window
Re-qualification on modification
Any change to the order parameters (address, service tier, options) requires a fresh qualification
Digital channels and BFFs must enforce qualification validity. Submitting a ProductOrder against an expired qualification is a common source of late-stage failures that could have been avoided with appropriate staleness detection.
Common Anti-Patterns in Service Qualification
1. Qualification as an Afterthought
Some architectures treat service qualification as an optional pre-check rather than a required gate. Orders are accepted and submitted regardless of whether qualification has been completed, relying on activation-time failure handling to catch infeasible requests.
This pattern multiplies the cost of failure. An order that fails during activation has already consumed order management processing, inventory reservation, and orchestration capacity. An order that fails at qualification consumes only a lightweight API call.
2. Embedding Qualification Logic in Activation
When qualification logic is not exposed through a dedicated interface like TMF645, it tends to migrate into the activation domain, where it is evaluated at provisioning time. This delays failure detection, increases orchestration complexity, and mixes technical feasibility concerns with execution logic.
3. Silently Accepting Alternatives
Returning an alternative service proposal without explicit customer confirmation is a source of downstream disputes and operational confusion. If the customer ordered 1 Gbps fiber and the network can only deliver 500 Mbps FTTC, that substitution must be surfaced and confirmed — not silently applied to the order.
4. Not Propagating Qualification Context
Discarding the qualification reference after order submission disconnects the ProductOrder from its feasibility basis. Activation systems that cannot reference the qualification outcome are forced to repeat checks, introducing latency and creating opportunities for divergence between what was qualified and what is provisioned.
Integration Pattern Summary
When TMF645 is implemented correctly, it provides a clean, early validation gate that prevents infeasible orders from entering the fulfillment pipeline and ensures that downstream processing operates on committed, technically verified requests.
Responsibility
Mechanism
Rationale
Validate technical feasibility early
TMF645 Service Qualification before TMF622 order submission
Prevents late failures and reduces orchestration complexity
Separate commercial from technical validation
TMF679 for eligibility, TMF645 for feasibility — independent calls
Allows each domain to evolve independently
Surface alternatives explicitly
Return AlternateServiceProposal with qualification result
Ensures customer confirmation before substitution is applied
Propagate qualification context to orders
Carry qualification ID and confirmed parameters in ProductOrder
Enables activation to skip redundant checks
Enforce qualification validity windows
Track expiry and re-qualify if window elapses or parameters change
Prevents order submission against stale feasibility data
Keep qualification logic behind the API
Validation in the domain, not in BFF or frontend
Eliminates duplication and maintains consistency across channels
What’s Next
This article examined TMF645 Service Qualification as a standalone domain: its structure, its role in the order lifecycle, its relationship to commercial qualification via TMF679, and the practical patterns required to implement it without introducing architectural fragility.
Together with the preceding articles in this series, the full order capture lifecycle is now covered from first product discovery through technical feasibility to order submission:
Article
Primary APIs
Focus
Customer Order Capture
TMF620, TMF679, TMF645, TMF622
End-to-end order capture lifecycle overview
TMF663 Shopping Cart Management
TMF663
Pre-order cart aggregation and session management
Service Qualification (this article)
TMF645
Technical feasibility validation in depth
Customer Order Management
TMF622, TMF641, TMF637
Order decomposition and orchestration
Service Activation
TMF641, TMF633, TMF638
Technical execution and inventory management
The next publication in the series will examine TMF620 Product Catalog Management in depth — exploring how catalog design decisions shape the complexity (or simplicity) of every downstream domain, from qualification through to activation.
Closing Principle
Closing Principle: Service Qualification is not a technical detail to be deferred. It is the architectural mechanism that aligns commercial commitment with operational capability. Systems that skip this step shift the cost of infeasibility downstream, where it is harder to handle, more expensive to recover from, and more visible to the customer.
TMF Open APIs – Pragmatic Patterns Using TMF641, TMF633, and TMF638
In the previous articles, we examined how customer intent is captured and standardized through TMF622 Product Ordering, and how Customer Order Management decomposes product orders and orchestrates lifecycle progression. Now we move to the final and often most complex domain: Service Activation and Operational State Management.
This domain represents the transition from commercial abstraction to technical execution — where real infrastructure constraints, asynchronous processes, and operational reality must be handled pragmatically. This article demonstrates how TMF641 Service Ordering, TMF633 Service Catalog, and TMF638 Service Inventory can be applied without introducing unnecessary orchestration complexity or tightly coupled fulfillment architectures.
The Service Activation Domain
The Service Activation domain operates under fundamentally different conditions than commercial order management. Where product ordering captures commercial intent, service activation is responsible for executing that intent within the operational environment. It translates service orders into concrete technical actions across network platforms, infrastructure components, and operational support systems.
Typical responsibilities within this domain include:
Responsibility
Description
Network provisioning
Configuring network elements, access technologies, or connectivity services
Resource configuration
Allocating and binding technical resources required for service delivery
Platform activation
Enabling services on application or service platforms (e.g., IPTV, VoIP, mobile)
OSS integration
Interacting with provisioning systems, resource managers, and inventory platforms
External vendor integration
Invoking third-party or partner systems required for service delivery
Operational characteristics in this domain differ significantly from upstream commercial systems. Service activation processes are typically:
Long-running — execution may span minutes, hours, or longer depending on infrastructure dependencies
Asynchronous — progress and results are delivered through events or status updates, not immediate responses
Partially executable — complex services may activate some components successfully while others require retries or remediation
Architectural Implication Because of these characteristics, the Service Activation domain must be designed to handle asynchronous execution, tolerate partial outcomes, and provide clear operational feedback to upstream order management systems. Architectures that assume synchronous, always-successful activation will fail at operational scale.
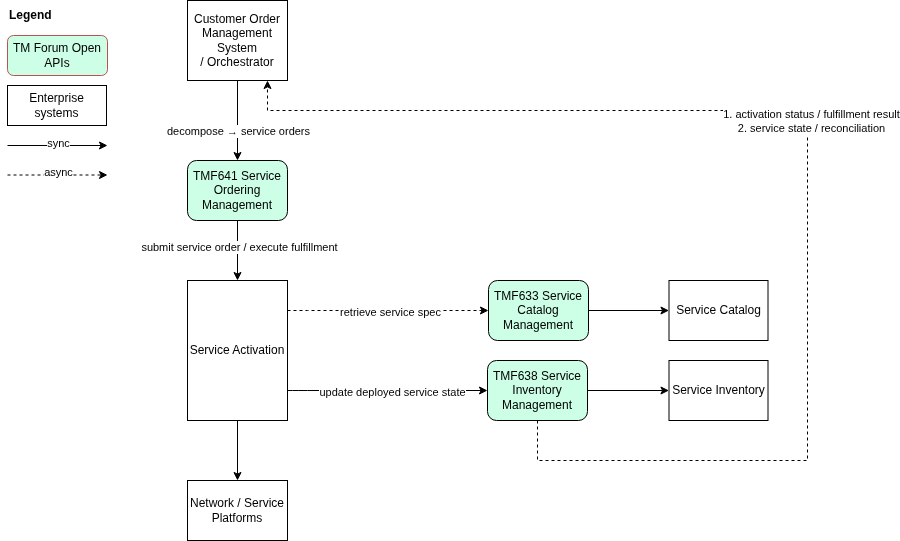
Service Ordering — TMF641
TMF641 Service Ordering Management API acts as the operational boundary between order orchestration and service execution. When Customer Order Management completes product order decomposition, the resulting service-level work requests are submitted through TMF641. At this point, responsibility shifts from commercial orchestration to technical fulfillment.
TMF641 therefore provides a stable execution interface that allows the orchestration layer to trigger service delivery while remaining independent from the internal design of activation systems.
What TMF641 Is — and Is Not
TMF641 IS…
TMF641 is NOT…
A contract for requesting service execution
A workflow engine
A lifecycle state tracking interface
A process definition framework
An operational boundary between domains
A platform for implementing provisioning logic
A stable integration surface for orchestrators
An internal activation system
Through this contract, the orchestrator can reliably initiate fulfillment activities without needing to understand how those activities are implemented internally. The key architectural rule is:
TMF641 enables execution requests — it does not define execution logic.
Separation of Responsibilities: Orchestration vs. Fulfillment
A clean architecture requires a clear distinction between order orchestration decisions and service activation execution. The two domains have fundamentally different roles:
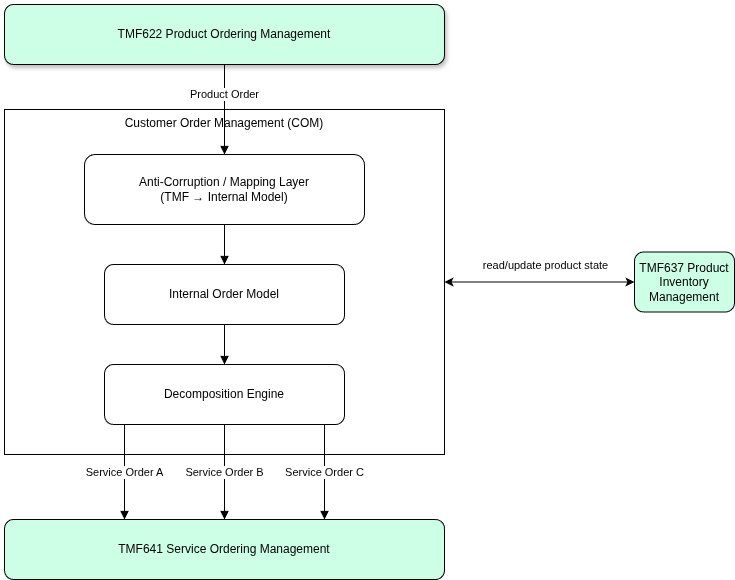
Customer Order Management (COM)
Service Activation Domain
Interprets the incoming TMF622 ProductOrder
Determines how provisioning must be performed
Decomposes the order into service-level actions
Identifies which OSS systems or network controllers to invoke
Submits ServiceOrders through TMF641
Manages dependencies between provisioning steps
Monitors fulfillment progress and advances product order state
Handles technical failures, retries, and recovery
In simple terms: COM decides what must be delivered. Service Activation decides how it is delivered.
Maintaining this separation prevents a common and costly anti-pattern: embedding provisioning logic inside the orchestration domain. When orchestration layers begin implementing detailed activation workflows, they become tightly coupled to network implementation details, making the system difficult to evolve and scale.
By keeping execution logic inside the fulfillment domain and using TMF641 purely as an execution contract, the architecture remains modular, maintainable, and resilient as both commercial and operational systems evolve independently.
Service Catalog — TMF633
TMF633 Service Catalog Management API provides the technical definitions of services required by fulfillment and activation domains. While product catalogs describe commercial offerings, the service catalog defines how those offerings are realized at the technical level.
The Service Catalog typically contains:
Service specifications describing the structure and characteristics of technical services
Resource requirements indicating dependencies on network or platform resources
Configuration templates used during provisioning and activation
Activation metadata that guides provisioning systems on how services should be instantiated
Activation and fulfillment systems may use TMF633 to resolve service specification details, validate technical configuration constraints, and retrieve provisioning parameters referenced in service orders.
Design-Time Reference, Not Runtime Dependency
From an architectural perspective, the Service Catalog should be treated as a supporting design-time and reference domain — not a synchronous runtime dependency on every activation request.
Recommended Approach Cache required catalog metadata within fulfillment systems at startup or on demand. Apply explicit versioning of service specifications to ensure predictable execution across releases. Avoid synchronous catalog lookups on critical provisioning paths — catalog unavailability must never block service activation.
This approach maintains activation performance, resilience, and operational stability, while ensuring that fulfillment systems rely on consistent and governed service definitions.
Execution Model — Asynchronous by Design
Service activation processes are inherently asynchronous and long-running. Unlike commercial order submission, technical provisioning typically involves multiple downstream systems, infrastructure platforms, and external integrations that cannot complete within a single synchronous request.
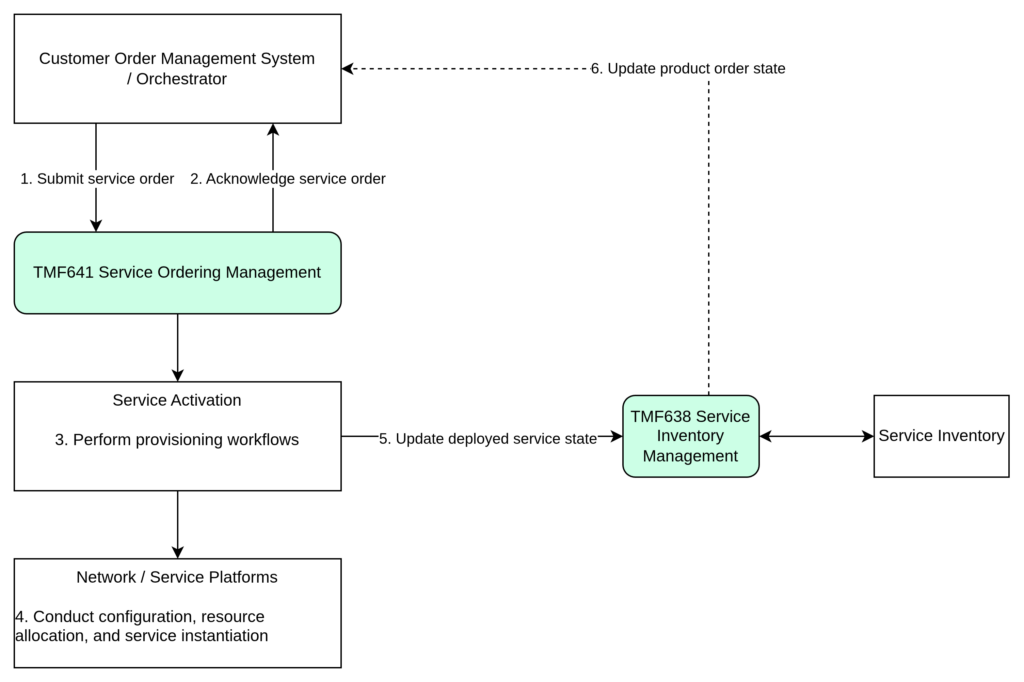
Typical Execution Lifecycle
Step
Actor
Action
1
COM
Submits ServiceOrder via TMF641
2
Activation Domain
Accepts and acknowledges the ServiceOrder
3
Activation Domain
Initiates internal provisioning workflows
4
Underlying Systems
Perform configuration, resource allocation, and service instantiation
5
Activation Domain
Emits lifecycle status updates as execution progresses
6
COM
Processes status events and advances product order state
Lifecycle States
During execution, the activation domain reports the following intermediate lifecycle states:
State
Meaning
COM Response
acknowledged
Request accepted for processing
Record confirmation; no state change
inProgress
Provisioning activities are executing
Maintain InProgress order state
pendingExternal
Waiting on an external system or vendor
Apply timeout monitoring; prepare retry
completed
Service successfully activated
Advance order to Completed; update TMF637
failed
Provisioning could not be completed
Enter recovery logic; evaluate retry or rollback
Design Principle Orchestration and order management domains must rely on event-driven feedback and lifecycle state transitions — not on synchronous completion of activation requests. A completed API call means the request was accepted. It does not mean the service was activated.
Service Inventory — TMF638
A fundamental architectural principle of fulfillment architecture is: the authoritative deployed state of services must be maintained in Service Inventory.
TMF638 Service Inventory represents the actual technical deployment of services in the network and platforms. It reflects what is really running in the infrastructure, independent of commercial intent or ordering processes.
TMF638 typically stores:
Deployed service instances and their identifiers
Active configurations and binding parameters
Relationships between services and underlying resources
Operational lifecycle state of each service (active, suspended, terminated, degraded)
Key Principle Service Inventory is not a tracking repository for orders. It is the source of truth for operational reality within the OSS landscape. Other domains — assurance, monitoring, reconciliation — must rely on TMF638, not on order state, to understand what is actually deployed.
During service activation, provisioning systems interact with infrastructure components and progressively update Service Inventory as deployment evolves — creating new service instances, modifying configuration, and recording operational state changes.
Feedback to the Order Domain
Once service activation begins, Customer Order Management must rely on asynchronous feedback from fulfillment and inventory domains to understand how execution is progressing. Two primary categories of signals flow back to the order domain.
1. Fulfillment Results
Fulfillment systems provide execution outcomes for service orders, typically through TMF641 interfaces. These signals drive the lifecycle of the commercial order managed through TMF622 and are used to:
A second category of signals originates from the operational environment — specifically, the service inventory maintained through TMF638. These updates represent the actual technical state of deployed services, independent of the order workflow.
Operational state signals are used for:
Inventory reconciliation and drift detection
Identifying service degradation or configuration inconsistencies
Triggering corrective actions in assurance or orchestration systems
Example Scenario A ProductOrder has been marked Completed in the order domain. Later, TMF638 Service Inventory reports that the corresponding service instance has entered a degraded operational state. In this situation: COM may initiate corrective workflows, assurance systems may trigger incident handling, and orchestration may request re-provisioning.
Order completion does not guarantee long-term operational correctness. Robust architectures must maintain continuous feedback loops between fulfillment, inventory, and order management.
Handling Reality Drift
In operational environments, reality drift occurs when the actual deployed state of a service diverges from the expected state defined during order fulfillment. This divergence is common in large distributed telecom environments and must be explicitly addressed in system design.
Delayed or incomplete responses from partner or third-party APIs
Partial provisioning failures
Some service components activate successfully while others fail silently
Out-of-band interventions
Operational changes applied during incident resolution without proper lifecycle tracking
Architectural Patterns for Managing Drift
1. Periodic Reconciliation
Scheduled reconciliation jobs compare the deployed service state stored in TMF638 with the real configuration observed in network or platform systems. These processes identify discrepancies and trigger corrective actions when necessary. Reconciliation frequency should be calibrated to the operational risk tolerance of the service type.
2. Event-Driven Inventory Updates
Modern architectures increasingly rely on event-driven mechanisms where network platforms emit state change events that update Service Inventory in near real time. This approach significantly reduces the window during which inconsistencies can exist undetected, and eliminates the latency inherent in scheduled reconciliation.
3. Domain-Specific Repair Workflows
When inconsistencies are detected — whether through reconciliation or event-driven signals — specialized repair workflows are triggered within the activation domain. These workflows may:
Reapply configuration to bring the network element back to the expected state
Restore missing or corrupted service components
Synchronize service state across all affected inventory and assurance systems
Escalate to manual intervention when automated repair is not viable
Avoiding Fulfillment Complexity Traps
Service activation architectures accumulate complexity over time — often through well-intentioned design decisions that solve short-term problems while creating long-term constraints. The following anti-patterns appear repeatedly in telecom BSS/OSS implementations and are worth addressing explicitly.
1. The Centralized Mega-Orchestrator
As activation requirements grow, there is a recurring temptation to introduce a single orchestration platform that owns the end-to-end fulfillment workflow — from ServiceOrder receipt through network provisioning, resource allocation, and inventory update. This approach typically starts as a pragmatic shortcut and gradually accumulates ownership of everything.
The consequences are predictable:
A single point of failure that affects all service types simultaneously
Deployment bottlenecks — every change to any service requires a release of the central platform
Performance degradation as order volumes grow and all execution serializes through one engine
Deep coupling between commercial product models and network implementation details
Preferred Approach Prefer domain-specific execution logic. Each service type or service family should own its activation workflow. Use TMF641 as the stable interface through which these domain-specific activators are invoked. Orchestration coordinates — it does not implement provisioning steps.
2. Overusing Workflow Engines
Visual workflow engines (BPM platforms, low-code orchestration tools) are valuable for genuinely complex, human-in-the-loop, or highly variable processes. However, many telecom provisioning flows are deterministic, rule-based, and predictable. Modeling these flows in a heavyweight workflow engine introduces operational overhead without architectural benefit.
Signs that a workflow engine is being overused:
Simple sequential activation steps modeled as multi-node workflows with branching logic
The workflow engine becomes the only way to understand what the system does
Changes to provisioning logic require workflow designer involvement rather than code review
Preferred Approach Use state-machine-based execution for deterministic provisioning flows. Reserve workflow engines for processes that are genuinely variable, approval-dependent, or require human intervention. Explicit state machines are easier to test, version, and reason about than visual workflow definitions.
3. Synchronous Activation Chains
A synchronous activation chain occurs when each provisioning step waits for the previous one to complete before proceeding — creating a long, blocking call chain that spans multiple systems. This pattern is fragile: a single slow or unavailable system causes the entire chain to stall or time out.
Common manifestations include:
Direct synchronous calls from the orchestrator into multiple downstream provisioning systems in sequence
Timeout values set high to accommodate slow external systems, masking latency problems
Error handling that propagates exceptions upward through the call chain rather than isolating failures
Preferred Approach Design activation flows as asynchronous command-and-event sequences. Each provisioning step emits a completion event. The next step is triggered by that event, not by a return value. This decouples execution timing, isolates failures, and allows individual steps to retry independently without affecting the rest of the workflow.
Integration Pattern Summary
When the Service Activation domain is implemented correctly, it becomes a well-bounded, operationally stable execution layer that supports both commercial agility and technical evolution. The following summarizes the key responsibilities and their rationale.
Responsibility
Mechanism
Rationale
Execute ServiceOrders
TMF641 Service Ordering API
Provides a stable, domain-independent execution contract
Resolve technical definitions
TMF633 Service Catalog (cached)
Decouples activation from catalog availability at runtime
Maintain authoritative deployed state
TMF638 Service Inventory
Ensures operational truth is available to all consuming domains
Emit lifecycle updates
Asynchronous events / callbacks
Allows orchestration to progress without blocking on activation
Decouple from commercial models
Anti-Corruption Layer at domain boundary
Allows product and service domains to evolve independently
Handle failures locally
Domain-specific retry and repair workflows
Prevents failure propagation into orchestration and order domains
When implemented correctly:
Operational complexity is isolated within the activation domain and does not leak into orchestration
The orchestration layer remains clean, focused on lifecycle coordination rather than provisioning detail
Individual activation domains can be scaled, replaced, or evolved without impacting upstream systems
TMF APIs serve as integration boundaries — not as architectural foundations for internal design
Closing the Lifecycle
This article concludes the three-part series on TM Forum Open API architecture. Across the trilogy, three distinct domains work in sequence to translate a customer’s commercial intent into a delivered, operational service.
Domain
Primary APIs
Core Responsibility
Customer Order Capture
TMF622 Product Ordering
Validates and standardizes commercial intent into a structured ProductOrder
Customer Order Management
TMF622, TMF641, TMF637
Decomposes the ProductOrder, orchestrates lifecycle, and coordinates fulfillment feedback
Service Activation & Inventory
TMF641, TMF633, TMF638
Executes technical provisioning and maintains authoritative operational state
TM Forum Open APIs serve a specific and bounded purpose in this architecture: they define domain boundaries, provide integration contracts, and establish interoperability standards between systems. They define the shape of the interface between domains — not the internal behavior of those domains.
A Closing Principle TMF APIs should never dictate internal architecture. A system that models its internal domain logic directly on TMF JSON structures will be brittle, difficult to evolve, and tightly coupled to API version cycles. Use TMF APIs at the boundary. Use domain models internally. The Anti-Corruption Layer is not optional — it is the mechanism that keeps these concerns separate.
Across all three domains, the architectural thread is consistent: own your domain logic, expose clean contracts, and use standard APIs as integration surfaces — not as blueprints for internal design. That separation is what makes telecom BSS/OSS architectures scalable, maintainable, and capable of evolving with both business and technology change.
Implementation Approaches: Platforms vs. Tailor-Made Development
Service Activation architectures can be implemented in several ways, each with distinct trade-offs in cost, flexibility, time-to-market, and long-term maintainability. The right choice depends on the operator’s scale, existing technology landscape, team capabilities, and the degree of domain specificity required.
Option 1 — Vendor Platforms
Established commercial platforms such as Nokia NSP, Ericsson OSS/BSS, IBM Sterling Order Management, and Netcracker provide pre-built fulfillment engines with native TMF API support, lifecycle management, and operational tooling. These solutions reduce time-to-market and bring proven operational patterns validated across large deployments.
Trade-offs to consider:
High upfront licensing and integration cost
Customisation of domain-specific business rules is constrained by the platform model
Vendor lock-in can limit architecture evolution and renegotiation leverage
Option 2 — Open-Source Platforms
Frameworks such as ONAP (Open Network Automation Platform) and OSM (Open Source MANO) provide community-driven orchestration and fulfillment capabilities with TMF alignment. These platforms are particularly relevant for operators pursuing open ecosystem strategies or needing multi-vendor network automation.
Trade-offs to consider:
Lower licensing cost, but significant investment in integration, configuration, and support
Community-driven TMF alignment varies in completeness across modules
Operational maturity depends heavily on internal DevOps and OSS expertise
Option 3 — Composable Frameworks
A growing number of teams adopt a composable approach: using a lightweight orchestration framework such as Temporal, Conductor, or Camunda for workflow coordination, while keeping domain-specific activation logic in purpose-built microservices that expose TMF641-compliant interfaces. This model offers high flexibility without building everything from scratch.
Trade-offs to consider:
Requires strong distributed systems expertise to operate reliably at scale
TMF alignment is manual — the team owns the integration contract design
Well-suited to organizations with mature engineering practices and evolving product portfolios
Option 4 — Tailor-Made Development
Full custom development — typically using runtimes such as Spring Boot, Quarkus, or Node.js combined with event streaming platforms like Apache Kafka or RabbitMQ — gives teams complete control over domain logic, state machine design, and integration contracts. This approach is justified when the domain logic is genuinely unique and no existing platform models it adequately.
Trade-offs to consider:
Highest initial investment in design, development, and operational tooling
Long-term maintenance ownership rests entirely with the internal team
Full alignment with domain model and TMF contracts — no platform constraints
Option 5 — Hybrid Approach
In brownfield environments, a hybrid strategy is often the most pragmatic path: retaining existing vendor platforms for stable, high-volume service types while introducing composable or tailor-made components for new services, digital channels, or domains requiring faster evolution. This allows incremental modernization without a full platform replacement.
Decision Matrix
The following matrix summarizes the key dimensions across all five approaches to support architectural decision-making:
Criterion
Vendor Platform
Open-Source Platform
Composable Framework
Tailor-Made
Hybrid
Time to market
Fast
Medium
Medium
Slow
Medium
Upfront cost
High
Low–Medium
Low–Medium
High
Medium–High
Vendor lock-in
High
Low
Low
None
Partial
TMF alignment
Native/partial
Community-driven
Manual
Full control
Mixed
Customisation
Limited
Moderate
High
Full
High
Operational maturity
High
Medium
Medium
Low initially
Medium–High
Team skill demand
Platform-specific
DevOps + OSS
Distributed systems
Strong dev team
Mixed
Best fit
Large operators,fast rollout
Cost-sensitive, open ecosystem
Flexible orchestration needs
Unique domain logic
Brownfield + evolution
A Constant Across All Approaches Regardless of the implementation path chosen, the architectural principles remain the same. TMF APIs define the boundaries. Domain logic stays internal. Operational state is always owned by Service Inventory. The platform or framework is an implementation detail — the domain model is the architecture.
Customer Order Management Domain Design & Orchestration with TMF622, TMF641, and TMF637
In the previous article, we examined how customer intent is captured and validated before being submitted as a standardized ProductOrder via TMF622. Now we move into the most critical domain of the lifecycle: Customer Order Management (COM).
Customer Order Management (COM) is where commercial intent is translated into technical execution. Done well, it keeps orchestration logic transparent, systems decoupled, and order state reliable. Done poorly — whether by becoming an ESB, a BPM monolith, or a thin pass-through — it becomes the bottleneck that breaks every large-scale telecom BSS deployment.
This article demonstrates how TMF622, TMF641, and TMF637 can be used in a pragmatic, domain-owned orchestration model — and explains the design decisions behind each choice.
The Role of Customer Order Management
Customer Order Management is frequently misunderstood. Its scope is often either too narrow (a simple API proxy) or too broad (a central workflow engine). Neither works at scale.
COM is NOT…
COM IS…
A simple pass-through integration layer
Owns the order lifecycle state
A centralized ESB routing all messages
Contains decomposition logic
A BPM monolith with complex workflows
Governs orchestration and coordination rules
A proxy that only exposes TMF schemas
Handles failures and exception recovery
Correlates fulfillment feedback and events
The distinction matters architecturally: COM owns behavior, not infrastructure. It does not route messages between systems — it governs how an order progresses through its lifecycle.
Architectural Boundary Recap
COM sits between the commercial and technical domains, acting as the translation and orchestration layer:
Downstream — TMF641 Service Ordering triggers technical execution (how it gets built)
Downstream — TMF637 Product Inventory reflects the customer-facing subscription state
Key Principle TM Forum Open APIs define the integration contracts between systems. Customer Order Management defines the lifecycle behavior — how orders progress, decompose, and react to fulfillment outcomes. These are separate concerns. Do not conflate the schema with the behavior.
From Product Order to Service Orders
What a ProductOrder Represents
A ProductOrder captures what a customer wants to buy — not how it gets delivered. It records the commercial agreement: which products or services were requested, at what price, under what terms, and by when.
For example, a ProductOrder might express: „Customer A wants 3 units of Fiber 1Gbps service, billed monthly, starting June 1“ — but it says nothing about which router will carry the traffic, which platform will host the service, or what provisioning steps engineers must follow.
A ProductOrder DOES represent…
A ProductOrder does NOT represent…
Commercial intent
Network topology or routing decisions
Customer-agreed products and terms
Service platform configuration
Requested start dates and pricing
Provisioning steps or activation sequences
Order-level identity and correlation ID
Technical resource allocation
In short: a ProductOrder answers „what was sold and agreed upon“ — not „how do we build or activate it.“ The downstream technical concerns belong to separate domains and are expressed through TMF641 ServiceOrders.
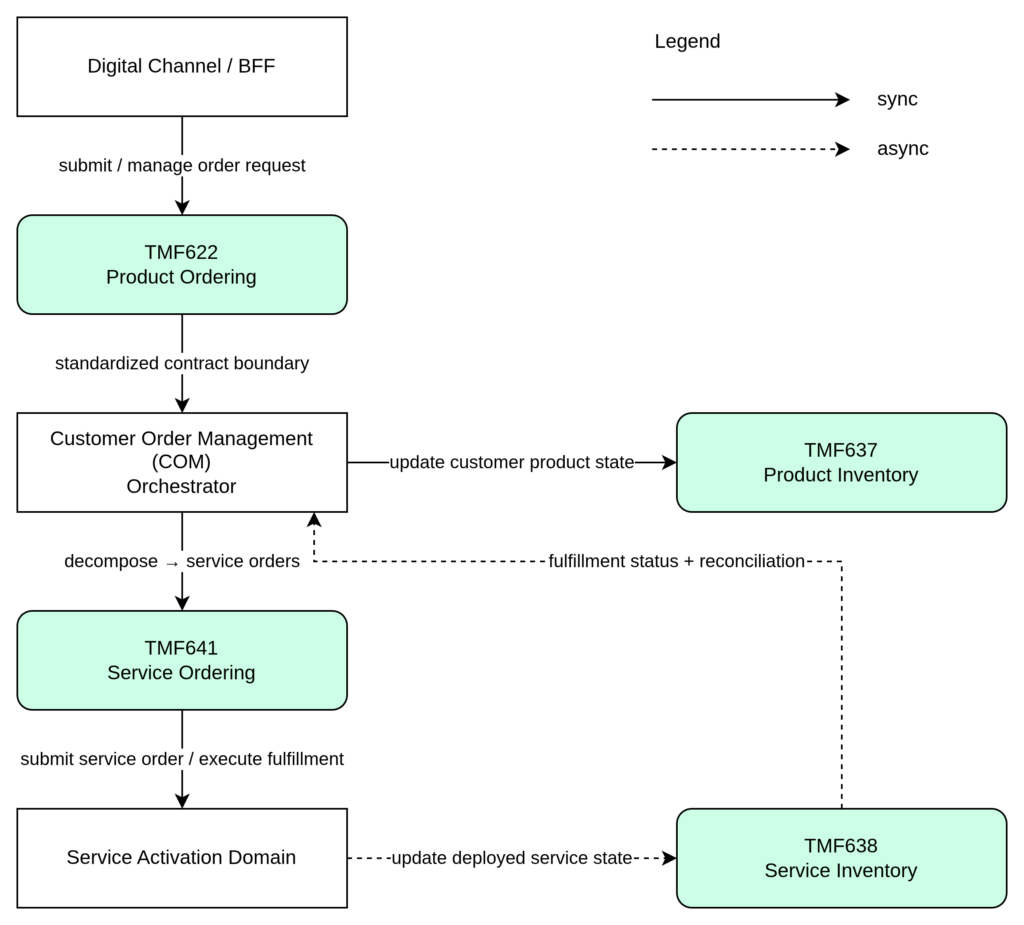
Order Decomposition
Inside COM, the ProductOrder must be decomposed into one or more ServiceOrders (TMF641). A single commercial product often requires multiple independent service activations:
Decomposes into: • Access service order (fiber circuit provisioning) • IP configuration service order (static IP assignment) • CPE provisioning service order (managed router configuration)
This decomposition must be:
Deterministic — the same ProductOrder always produces the same set of ServiceOrders
Version-aware — decomposition rules must account for product catalog changes over time
Idempotent — reprocessing an order due to failure must not create duplicate ServiceOrders
Decomposition as Domain Logic
Decomposition logic belongs inside COM, not in integration layers or external workflow engines. It should:
Use product-to-service mapping rules defined within the domain
Operate on internal domain models, not directly on TMF JSON structures
Be isolated from external API schema changes through an Anti-Corruption Layer (ACL)
The recommended mapping approach is a five-stage pipeline:
Step
Stage
Description
1
Receive
Accept TMF622 ProductOrder as the external integration contract
2
ACL Transform
Decouple the TMF schema from internal models via an Anti-Corruption Layer
3
Domain Mapping
Map to the internal Order domain model used by the Order Management system
4
Decomposition
Execute the Order Decomposition Engine to generate technical fulfillment actions
5
Submission
Generate and submit TMF641 ServiceOrder requests to downstream systems
This approach avoids the anti-pattern of designing the entire system around TMF JSON structures — a trap that makes internal logic brittle whenever the external API evolves.
Orchestration Without a Monolith
One of the most common architectural traps in telecom implementations is introducing a centralized BPM or workflow engine that gradually absorbs the entire order lifecycle. These systems tend to:
Embed complex orchestration logic in large, opaque workflow definitions
Own state management in a way that makes external observation difficult
Become performance and change bottlenecks as order volumes grow
A more pragmatic alternative is state-machine-based, event-driven orchestration. Instead of a visual workflow engine, implement orchestration using:
An explicit Order State Machine that governs lifecycle transitions
Domain events that communicate progress and trigger next actions
Clear, testable transition rules that define how the order moves between states
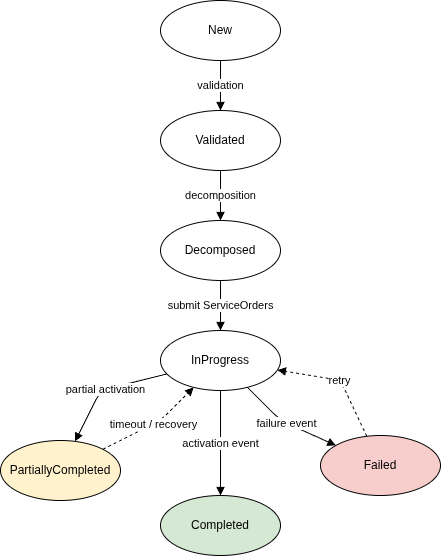
Order Lifecycle State Machine
The order lifecycle moves through the following states, each triggered by specific operational events:
State
Trigger Event
Next Action
Validated
Order accepted and validated
Begin decomposition
Decomposed
ServiceOrders generated
Submit to TMF641
InProgress
At least one ServiceOrder submitted
Await fulfillment events
PartiallyCompleted
Some components succeeded, some pending/failed
Evaluate retry or compensation
Completed
All components succeeded
Update Product Inventory (TMF637)
Failed
Unrecoverable failure across components
Trigger compensation / notify upstream
Why State Machines Over Workflow Engines?
Transparent — the current state and permitted transitions are always visible and auditable Testable — each transition rule can be validated independently, without running a full workflow Scalable — state is explicit data; it scales horizontally without centralized orchestration bottlenecks
Handling Asynchronous Feedback
Service execution rarely completes synchronously. After COM submits ServiceOrders via TMF641, fulfillment systems process requests and return status updates asynchronously. COM must be designed to handle this correctly.
What COM Receives
Typical asynchronous status updates from fulfillment systems include:
inProgress — fulfillment has started but is not yet complete
completed — the service component was successfully activated
failed — activation failed, with error context
partialActivation — some sub-components succeeded, others did not
How COM Must Respond
For each incoming event, COM must:
Correlate the feedback message with the correct orderItem using the correlation ID
Update the internal order state based on the outcome
Evaluate whether the overall ProductOrder can advance to the next lifecycle stage
Design Principle Order state progression must be driven by actual fulfillment outcomes — not by the immediate response of synchronous API calls. A 200 OK from TMF641 means the ServiceOrder was accepted, not that the service was activated.
Partial Failures and Recovery
In real-world fulfillment, not all service components succeed simultaneously. One component may complete while another fails due to a resource shortage, a downstream timeout, or a configuration conflict. COM must have a defined recovery strategy for each scenario.
Use explicit retry counters to prevent infinite loops
Compensate
Partial success where completed steps must be undone
Compensation logic must be defined per service type
Roll back
Critical failure where no partial state is acceptable
Ensure rollback is idempotent and auditable
Mark PartiallyCompleted
Some components are acceptable without others (by business rule)
Requires explicit product catalog guidance on optionality
Recommended Approach Keep retry logic inside the domain layer, where business rules are well understood. Avoid embedding retry behavior in external workflow or orchestration platforms. Maintain explicit retry counters. Unbounded retries are an operational risk, not a safety net.
Product Inventory Update — TMF637
Once fulfillment reaches a stable state, COM updates the Product Inventory using TMF637. A critical architectural principle governs this step: product and service inventories must remain separate.
TMF638 Service Inventory reflects technical service reality in the network and platforms
TMF637 Product Inventory represents the customer-facing subscription state
COM acts as the translation and alignment layer between these two domains. It maps service states to product states and triggers reconciliation if mismatches occur.
State Mapping
TMF641 Service State
TMF637 Product State
Notes
completed
active
All components fulfilled; customer-visible
suspended
suspended
Service paused; subscription retained
failed
pendingTermination or failed
Business rule governs customer notification
partialActivation
pendingActive
Awaiting remaining components; not yet customer-visible
terminated
terminated
Service decommissioned; subscription closed
This mapping ensures that customer-visible subscription status accurately reflects the underlying service activation state, while preserving the domain separation between service operations and product lifecycle management.
Synchronous vs Asynchronous Interactions
In order management architecture, it is critical to clearly separate synchronous API interactions from asynchronous operational feedback. Conflating the two leads to brittle, blocking systems that fail unpredictably at scale.
Synchronous Interactions — Request Acceptance
Synchronous calls are used for request submission and immediate validation. They confirm that a request has been received and is structurally valid — but they do not guarantee fulfillment.
Submission of customer orders via TMF622 Product Order
Creation of service fulfillment requests via TMF641 Service Order
What a synchronous response guarantees: • The request is structurally valid • It has been accepted for processing • Processing has started
What it does NOT guarantee: fulfillment completion. Long-running fulfillment activities must never block synchronous API calls.
Asynchronous Interactions — Fulfillment Feedback
Actual service fulfillment occurs asynchronously across multiple downstream systems. These systems emit events or callbacks that COM must process to advance the order lifecycle:
Service activation progress and completion updates
Failure notifications from fulfillment systems
Inventory reconciliation events from TMF638 or TMF637
Why This Separation Matters
Benefit
Explanation
Resilience
Failures in fulfillment systems do not block or degrade API responses
Scalability
Long-running operations are handled through events rather than blocking threads
Transparency
Order state progression is driven by real fulfillment outcomes, not API latency
Loose Coupling
Upstream systems are not tightly bound to downstream execution timing
Avoiding Common Anti-Patterns
1. COM as an ESB
COM must not become a routing hub for all integrations. It owns order lifecycle state and decomposition logic — nothing more. When COM starts routing messages between unrelated systems, it accumulates accidental complexity and becomes a single point of failure.
2. Deep Coupling to TMF Models
Internal state machines and domain logic must not depend directly on TMF JSON structures. External schemas change with API versions. An Anti-Corruption Layer decouples the external contract from the internal model, allowing both to evolve independently.
3. Centralized Workflow for Everything
Not every step in the order lifecycle requires BPM modeling. Many telecom fulfillment flows are predictable, rule-driven, and state-based. Introducing a visual workflow engine for these flows adds operational overhead without architectural benefit. Start with a state machine; escalate to a workflow engine only when the complexity genuinely demands it.
Integration Pattern Summary
When implemented correctly, Customer Order Management is a domain-focused orchestrator — not a middleware platform. It keeps orchestration complexity contained, treats TMF APIs as integration boundaries rather than internal data models, and produces systems that remain evolvable as products and technology change.
COM should:
Own lifecycle state — no external system should drive order progression
Decompose ProductOrders deterministically and idempotently
Trigger ServiceOrders via TMF641 and treat the response as acceptance, not completion
Process asynchronous fulfillment events to drive state transitions
Update Product Inventory via TMF637 only after reaching a stable fulfillment state
Orchestration complexity is contained within a single, observable domain
TMF APIs remain clean integration boundaries, not architectural foundations
Systems remain independently deployable and evolvable
What’s Next
In the next article, we move into the Service Activation domain and explore how technical execution is handled once COM has submitted its ServiceOrders:
TMF641 execution patterns and state management
The role of TMF633 Service Catalog in driving activation logic
TMF638 Service Inventory as the authoritative deployed state
Reconciliation strategies for handling drift between network reality and customer product state
(Not TMF633 — that’s Service Catalog. The Shopping Cart API is TMF663.)
In modern telecom architectures, one recurring question appears during digital transformation programs:
“Do we really need a standardized Shopping Cart API?”
With microservices, composable frontends, and powerful BFF layers, many teams assume the shopping cart can simply be implemented inside the digital channel.
So where does TMF663 actually fit? And is it still relevant?
Let’s analyze this architecturally.
What TMF663 Is
TMF663 – Shopping Cart Management is designed to:
Manage pre-order cart state,
Persist selected product offerings,
Support configuration updates,
Transition cart into a ProductOrder.
It is not:
A pricing engine,
A qualification engine,
An orchestration engine,
A product catalog.
It exists in the pre-order domain, before TMF622 Product Ordering.
The Core Architectural Question
The real question is not:
“Do we need TMF663?”
The real question is:
“Where should cart state live in a distributed architecture?”
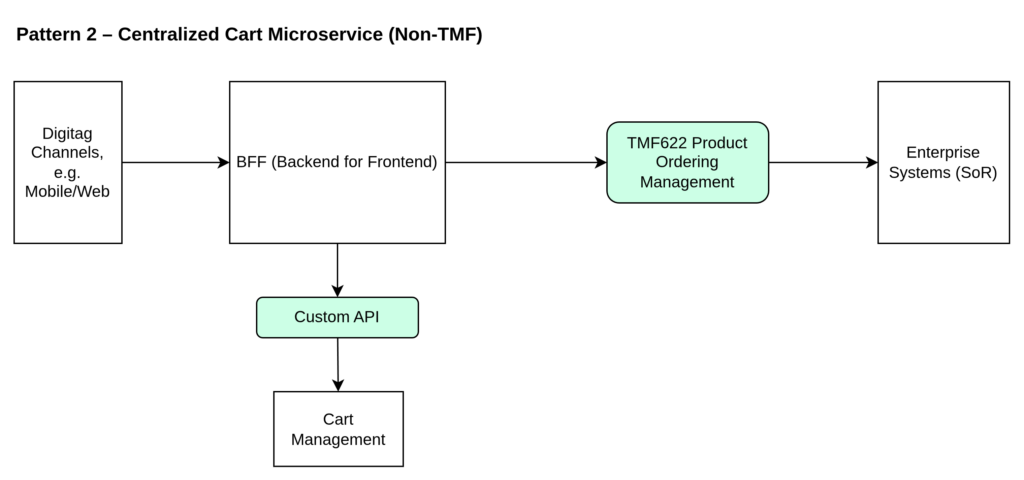
There are three common patterns.
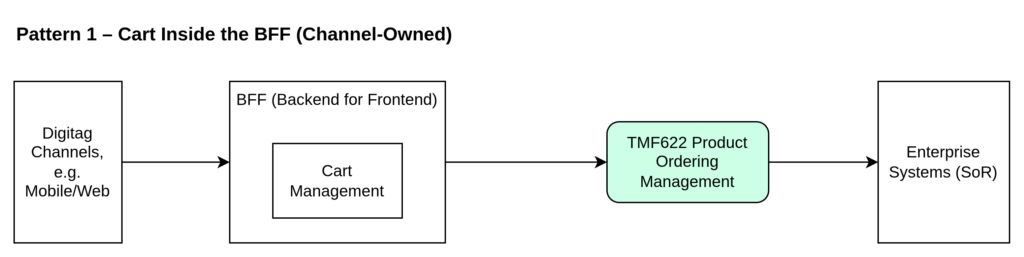
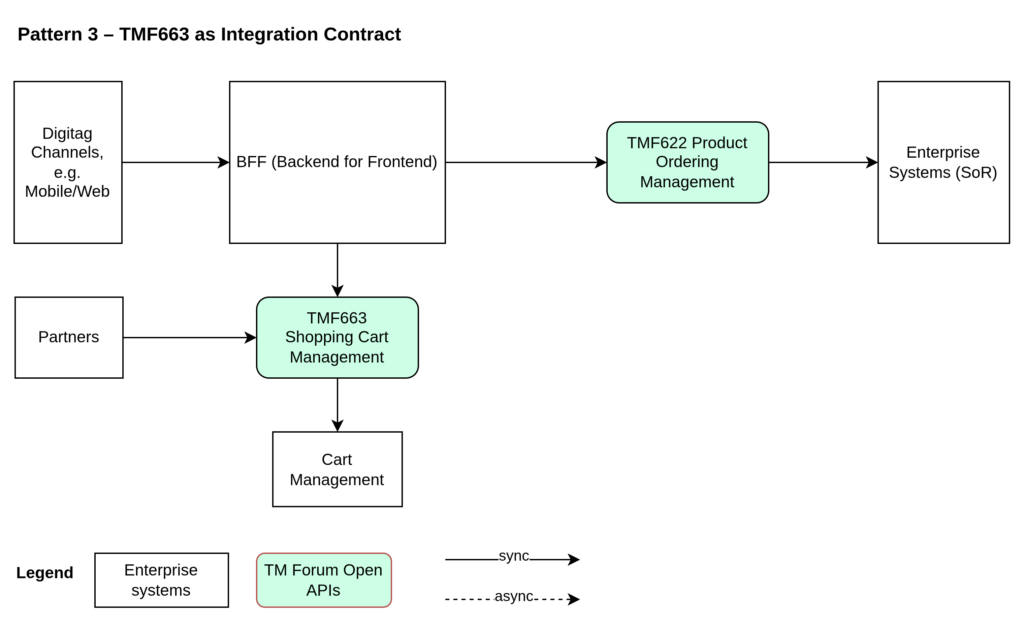
Pattern 1 – Cart Inside the BFF (Channel-Owned)
In this approach:
Digital Channels (e.g., Mobile/Web) interact directly with the BFF (Backend for Frontend).
Cart Management is implemented inside the BFF.
The BFF submits orders to TMF622 Product Ordering Management.
TMF622 integrates with Enterprise Systems (SoR).
Architectural Characteristics
In this pattern, the shopping cart is not a separate domain capability. It is embedded within the channel layer.
The BFF is responsible for:
Managing cart state
Handling product configuration
Preparing the ProductOrder payload
Calling TMF622
There is no reusable cart service outside the channel context.
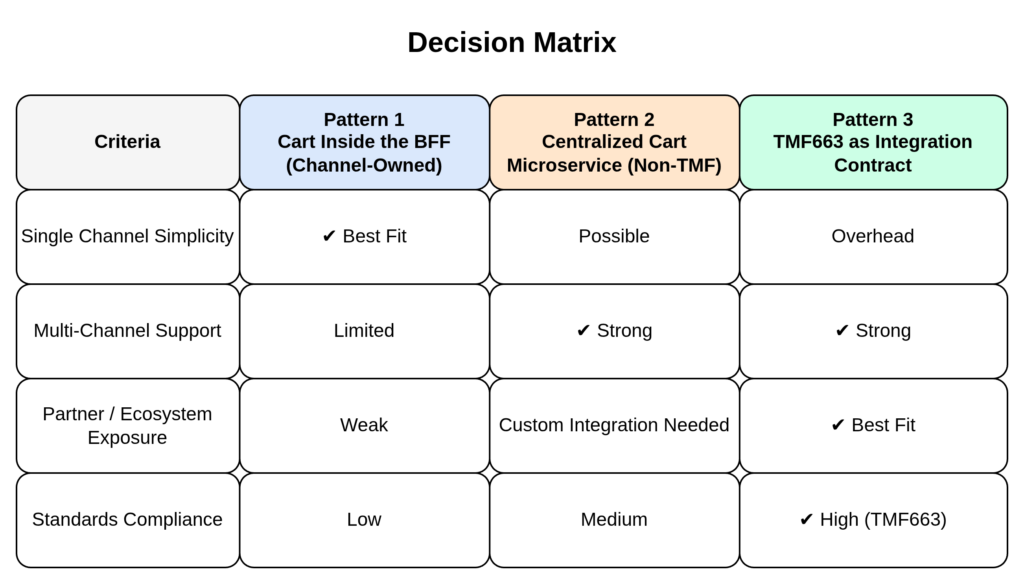
When It Fits
Single or tightly controlled digital channel
Minimal partner exposure
Strong UX ownership
Fast delivery priority
Architectural Trade-Off
Cart logic is tightly coupled to channel implementation. Reusability across channels or partners is limited.
Submit the Executable Order Create and submit a formal customer order through:
TMF622 – Product Ordering
Orchestrate and Decompose the Order Coordinate fulfillment logic and manage order state within the Order Management domain (typically consuming TMF622 events and interacting with downstream APIs such as TMF641 where required)
Activate and Provision Services Trigger technical fulfillment and manage service lifecycle using:
TMF641 – Service Ordering
TMF638 – Service Inventory
In this model:
Qualification verifies commercial and technical feasibility first.
Only valid, sellable configurations are added to the cart.
The cart stores already qualified commercial intent.
The formal order lifecycle begins only when a TMF622 ProductOrder is submitted. TMF663, if used, sits between qualification and order submission. Its purpose is to organize and persist validated intent – not to perform eligibility or orchestration logic. When designed this way, the cart becomes a clean transition layer. When qualification is skipped or deferred, the cart turns into a staging area for errors that will surface later in order management or activation.
Conclusion
There is no single “correct” way to structure shopping cart management.
As we’ve seen, you can:
Keep the cart inside the digital channel,
Implement a dedicated domain cart service, or
Expose TMF663 as a standardized integration boundary.
Each option is valid — depending on your scale, channel strategy, partner model, and architectural maturity.
Now that you see the different patterns and trade-offs, the question is no longer “Do we need TMF663?”
The real question becomes:
Which option best fits your context, complexity, and long-term integration goals?
Architecture is about making deliberate choices — not following standards blindly.
Telecommunication architectures often struggle not with service activation or network execution, but with the very first step of the lifecycle: translating customer intent into a clean, valid order.
Many transformation programs introduce complexity at this stage by tightly coupling digital channels to backend systems, embedding business rules inside frontends, or overloading orchestration platforms with responsibilities that belong to domain boundaries.
This article explores a pragmatic approach to customer order capture using TM Forum Open APIs as stable integration contracts — focusing on how commercial validation, technical feasibility, and order submission can be implemented without creating architectural bottlenecks.
The discussion builds on the master architecture presented in TM Forum Open APIs Without the Complexity Trap and focuses specifically on the capture layer.
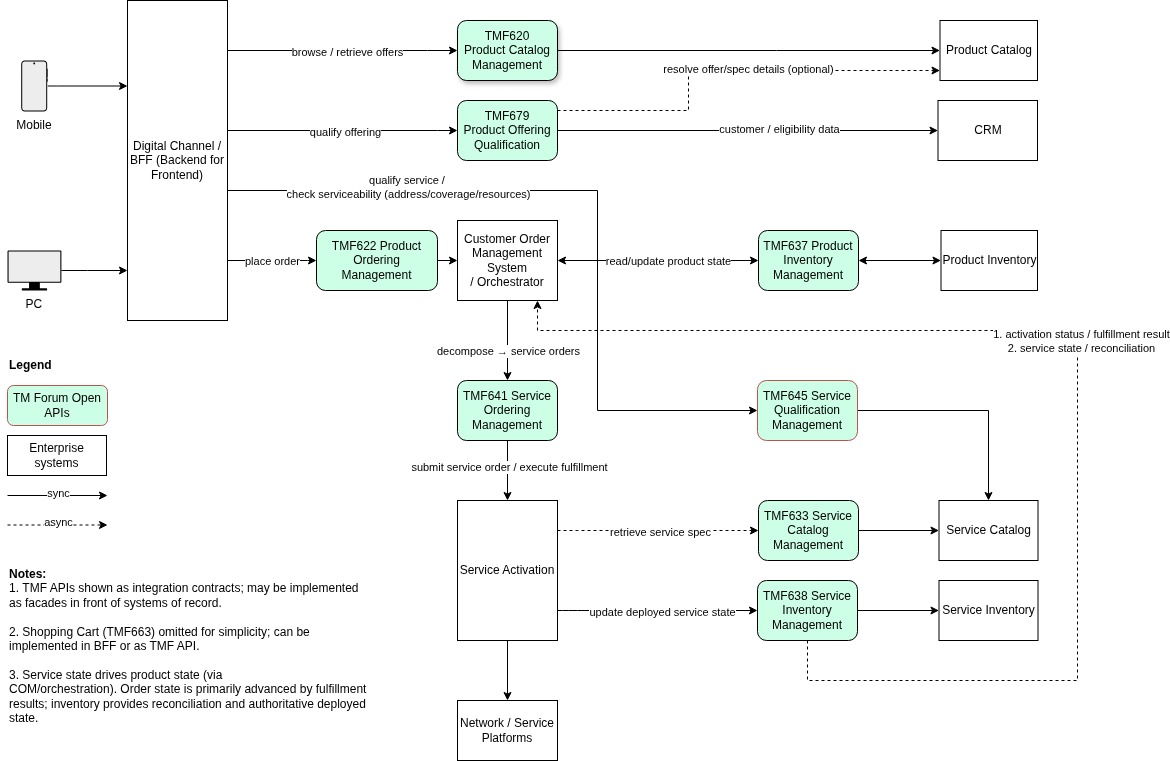
Diagram 1 – Customer Order Capture Flow
Architectural Scope
This article focuses on the commercial entry point of the lifecycle — the transition from customer interaction to standardized product order submission.
Core APIs covered:
TMF620 — Product Catalog Management
TMF679 — Product Offering Qualification
TMF645 — Service Qualification
TMF622 — Product Ordering Management
These APIs represent the boundary between digital engagement and downstream operational domains.
Key Architectural Principle
TM Forum APIs should act as:
stable integration contracts
domain boundaries
interoperability interfaces
They should NOT:
define internal data models
dictate orchestration logic
force digital channels to mirror backend complexity.
The goal of customer order capture is simple:
Produce a clean, validated ProductOrder representing commercial intent.
Everything else belongs downstream.
Engagement Layer — Digital Channel / BFF
Customer interaction begins in digital channels:
Web portals
Mobile applications
Partner systems
The BFF (Backend-for-Frontend) plays a crucial role:
Aggregates multiple backend APIs
Shields frontend from domain complexity
Maintains UX-specific workflows.
However, a common anti-pattern is turning the BFF into a business logic engine.
Pragmatic rule:
Validation logic lives behind TMF APIs, not inside the channel.
Product Discovery — TMF620 Product Catalog
The lifecycle begins with browsing commercial offerings via TMF620.
Responsibilities:
Retrieve product offerings
Resolve bundles and configurations
Provide structured product metadata.
Architectural pattern:
TMF620 often acts as an API facade over legacy catalog platforms.
Benefits:
Stable contract for digital channels
Decoupling from catalog implementation
Incremental modernization possible.
Important design choice:
The catalog provides information — it does not validate eligibility.
The previous article introduced a pragmatic architectural approach for using TM Forum Open APIs as integration contracts rather than internal system models. While high-level architecture diagrams help clarify domain boundaries, the real complexity in telecom systems appears when commercial intent becomes operational execution — specifically within the order lifecycle.
This article moves from architectural vision to practical execution. It describes how product orders progress through their lifecycle using TMF622 Product Ordering and TMF641 Service Ordering, demonstrating how orchestration can remain lightweight, domain-driven, and resilient without introducing unnecessary middleware complexity.
The goal is not to describe TM Forum specifications themselves, but to show how they can be applied pragmatically in real enterprise environments.
The Real Problem: Order Lifecycle Complexity
Many telecom implementations encounter difficulty not because of TM Forum APIs, but because of architectural decisions around orchestration.
Common patterns seen in real projects include:
Treating TMF622 as a central orchestration engine.
Introducing heavy workflow platforms controlling all lifecycle logic.
Tight coupling between ordering, inventory, and fulfillment systems through synchronous dependencies.
Modeling internal systems directly on TMF schemas.
These approaches often lead to rigid architectures that are difficult to evolve and slow to deliver change.
A pragmatic alternative is to treat TMF APIs as integration boundaries while keeping orchestration logic inside a domain-owned Order Management or Customer Order Management (COM) component.
TMF641 bridges commercial orders with technical fulfillment.
Asynchronous feedback drives state transitions.
High-Level Order Lifecycle Flow
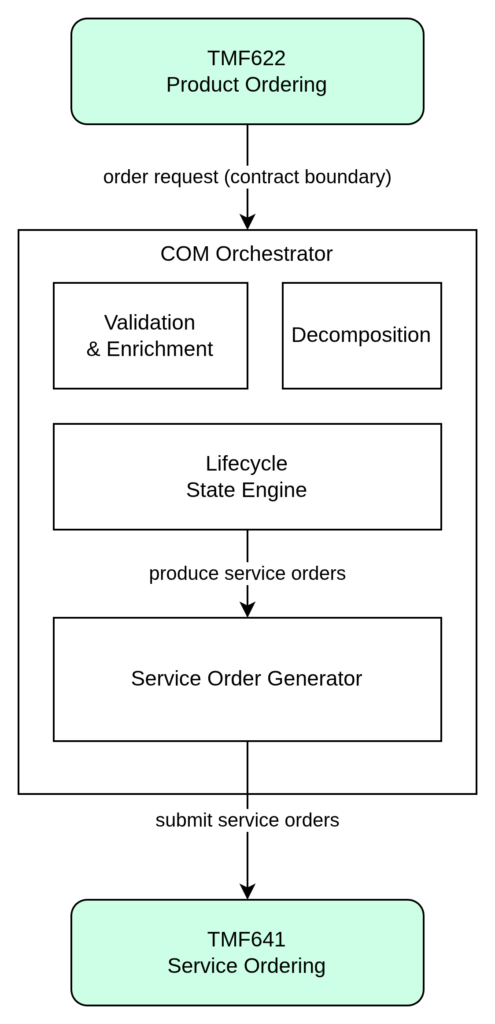
The lifecycle begins when a customer submits a confirmed purchase through a digital channel. The request enters the system through TMF622 Product Ordering, which acts as a standardized boundary between commercial engagement and operational processing.
Internally, the Customer Order Management System assumes responsibility for:
validating order context,
managing lifecycle state,
decomposing product orders into service-level actions,
coordinating fulfillment execution.
Instead of executing orchestration inside TMF interfaces themselves, the COM operates as a domain service that interprets external contracts and manages internal workflows independently.
The typical lifecycle stages include:
Order capture through TMF622.
Validation and enrichment.
Product-to-service decomposition.
Service order creation via TMF641.
Fulfillment execution.
Asynchronous feedback processing.
Product and service inventory synchronization.
This separation maintains architectural clarity: TMF APIs remain interoperability interfaces, while orchestration logic stays within the owning domain.
Synchronous vs Asynchronous Interaction Strategy
One of the most important architectural decisions involves determining which interactions should remain synchronous and which should become event-driven.
In pragmatic telecom architectures:
Synchronous interactions are used where immediate validation or deterministic responses are required, such as:
order submission,
qualification checks,
catalog queries.
These operations benefit from predictable response patterns and straightforward transactional behavior.
However, fulfillment execution and lifecycle progression are inherently long-running processes. Attempting to model them synchronously introduces fragility and operational risk.
Therefore, asynchronous workflows should drive:
fulfillment status updates,
service activation progress,
inventory reconciliation,
order lifecycle transitions.
Asynchronous feedback allows independent scaling of fulfillment components and reduces tight coupling between systems.
Order Orchestration Without Overengineering
A common misconception is that complex telecom order orchestration requires a centralized workflow engine controlling every step.
While workflow platforms can provide visibility, they frequently become architectural bottlenecks:
forcing global coordination,
introducing additional operational layers,
making domain ownership unclear.
A more pragmatic approach uses a domain-owned orchestrator inside the Customer Order Management layer.
Key characteristics include:
lightweight state machines rather than monolithic workflows,
event-driven state transitions,
clear ownership of lifecycle progression.
The orchestrator reacts to events such as:
service activation completion,
fulfillment failure notifications,
inventory updates.
This pattern enables flexibility while maintaining clear domain responsibility.
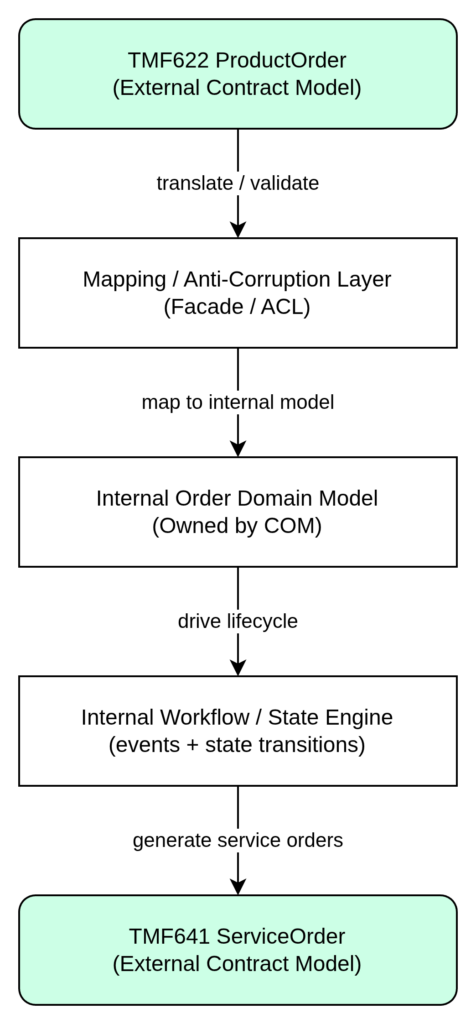
Data Model Boundaries and Anti-Corruption Layers
Another critical design principle is maintaining separation between external TMF models and internal domain representations.
TMF data structures define integration contracts between systems. They should not automatically dictate internal modeling.
Instead:
TMF622 represents the external product order contract.
The COM translates this structure into internal order representations.
TMF641 service orders are generated from internal models.
Inventory updates are mapped back into standardized interfaces.
This anti-corruption approach protects internal services from schema drift and prevents cascading changes across domains when specifications evolve.
Inventory Synchronization and Lifecycle Authority
In this architecture, service inventory and product inventory play distinct roles.
TMF638 Service Inventory represents operational reality — the authoritative record of deployed technical services.
Fulfillment systems update service inventory as activation progresses.
These updates flow asynchronously back to the COM, where they serve two purposes:
advancing order lifecycle state,
enabling reconciliation between expected and actual deployment.
Once service deployment reaches a stable state, the COM updates TMF637 Product Inventory to reflect customer-facing subscription state.
Separating technical reality from commercial representation avoids coupling operational systems directly to customer-facing domains.
Common Architecture Mistakes
Several recurring anti-patterns appear in telecom transformations:
Using TMF622 as a workflow engine rather than an integration boundary.
Introducing synchronous dependencies on inventory during fulfillment.
Modeling internal services directly around TMF schemas.
These decisions increase complexity and reduce flexibility over time.
A pragmatic architecture instead prioritizes domain ownership, asynchronous lifecycle management, and contract-based integration.
Conclusion
The order lifecycle represents the transition from commercial intent to operational execution — and therefore is where integration architecture decisions have the greatest impact.
By treating TM Forum Open APIs as stable integration contracts and placing orchestration responsibility inside a domain-owned order management layer, organizations can achieve:
reduced coupling,
improved resilience,
clearer ownership boundaries,
and incremental evolution of legacy environments.
This approach allows teams to leverage TMF standards without introducing unnecessary architectural complexity.
What’s Next
This article focused on the high-level lifecycle and orchestration approach. In the next publications, we will dive deeper into detailed execution flows, including:
asynchronous event-driven lifecycle patterns,
practical request/response sequences,
data model mappings between TMF contracts and internal domains,
and reconciliation logic between service and product inventory.
Pragmatic Integration Patterns Using TMF620, TMF679, TMF622, TMF637, TMF641, TMF633, TMF645 and TMF638
Telecommunication architectures increasingly adopt TM Forum Open APIs to standardize integration across OSS/BSS ecosystems. These APIs provide a shared semantic language that enables interoperability between systems from different vendors and internal domains.
However, real-world implementations often struggle — not because of the APIs themselves, but because of how they are applied architecturally. Many organizations introduce unnecessary complexity: heavy middleware layers, rigid orchestration engines, or “TMF-first” internal modeling that couples everything to standard schemas and slows delivery.
This article presents a set of pragmatic integration prototypes demonstrating how core TM Forum APIs can be used effectively as stable integration contracts, while avoiding common complexity traps. The goal is to show an approach that is realistic for enterprise landscapes, but still incremental and maintainable.
The prototypes focus on the following APIs:
TMF620 Product Catalog Management
TMF679 Product Offering Qualification
TMF622 Product Ordering Management
TMF637 Product Inventory Management
TMF641 Service Ordering Management
TMF633 Service Catalog Management
TMF645 Service Qualification Management
TMF638 Service Inventory Management
Together, these APIs cover a complete lifecycle from product discovery and qualification, through ordering and orchestration, to fulfillment and operational tracking.
Architectural principles
Before exploring specific patterns, it is important to clarify the architectural perspective used in these prototypes.
TM Forum APIs should be treated as:
stable integration contracts
domain boundaries between systems
interoperability interfaces
They should not automatically define internal architecture, internal data models, or orchestration strategy.
The core principles applied here:
Use TMF APIs as integration boundaries rather than internal models.
Implement TMF APIs as API facades / anti-corruption layers when integrating legacy or vendor systems.
Keep orchestration inside a domain-owned Order Management / Orchestrator (COM) rather than in external workflow platforms by default.
Combine synchronous APIs at the boundaries with asynchronous lifecycle feedback where it improves resilience and decoupling.
Support incremental modernization rather than big-bang transformations.
In practice, many telecom transformations fail when TM Forum APIs are treated as architectural frameworks rather than interoperability contracts.
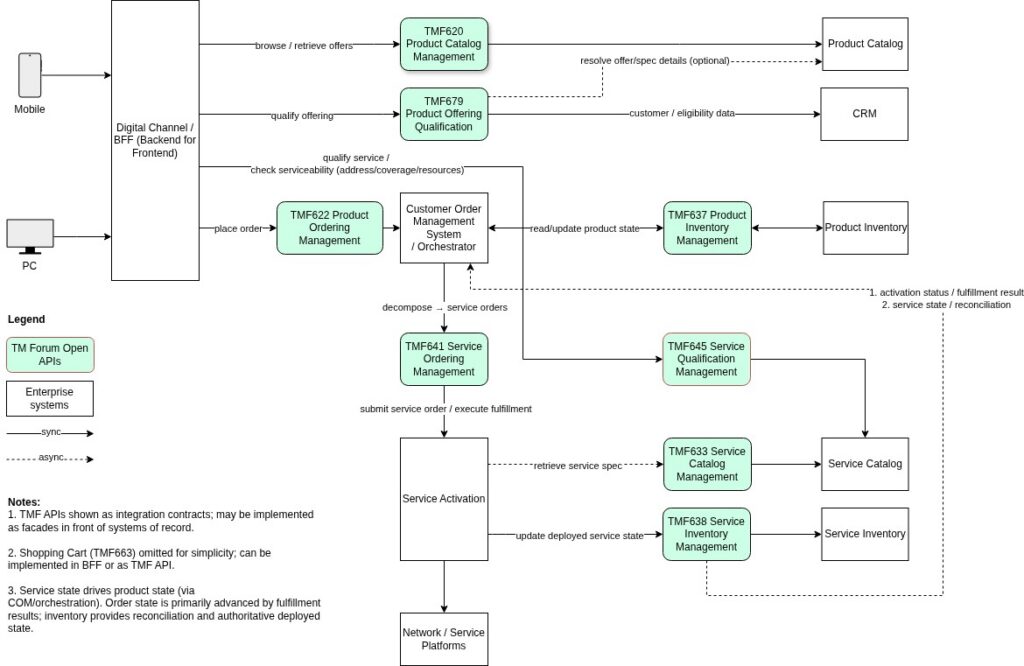
End-to-End flow overview
To understand how these TM Forum Open APIs work together in a pragmatic integration architecture, it is useful to examine the complete lifecycle from customer interaction to operational service state.
Rather than presenting TMF APIs as isolated endpoints, this architecture shows how they form a set of integration contracts between clearly separated domains: digital engagement, commercial management, order orchestration, and service fulfillment.
The goal is not to prescribe a rigid framework, but to illustrate how standardized APIs can be combined into a coherent flow while preserving domain autonomy and minimizing coupling between systems.
Several important design choices shape this architecture:
Digital channels interact only with stable TMF contracts rather than internal system implementations.
Qualification is separated into commercial validation (product offering qualification) and technical feasibility (service qualification), preventing late-stage failures during fulfillment.
Product ordering defines the boundary between commercial intent and operational execution.
A domain-owned order management system performs orchestration, avoiding centralized integration bottlenecks.
Operational reality is reflected through service and product inventories, enabling lifecycle tracking and reconciliation.
The diagram below presents a high-level view of this lifecycle, emphasizing architectural responsibilities rather than implementation details.
The lifecycle begins in a Digital Channel / BFF (Backend-for-Frontend). The BFF performs synchronous interactions with commerce-facing APIs:
TMF620 Product Catalog is used to browse and retrieve commercial offerings.
TMF679 Product Offering Qualification validates eligibility and configuration constraints for the selected offering. In some implementations, qualification may require resolving offer/spec details from the catalog — this is treated as an optional supporting lookup, not a mandatory dependency.
TMF645 Service Qualification checks serviceability (address / coverage / resource constraints). This keeps “can we technically deliver this?” separate from “is this product commercially valid?”, reducing hidden coupling and late-order failures.
Once the customer confirms the purchase, the channel submits the request via TMF622 Product Ordering. This API acts as a key architectural boundary: it captures commercial intent using a standardized contract, while shielding downstream systems from channel-specific variations.
Behind TMF622 sits the Customer Order Management System / Orchestrator (COM). The COM owns the order lifecycle and orchestration logic and is responsible for decomposing a product order into service-level actions. The COM then triggers fulfillment through TMF641 Service Ordering.
Service activation executes the service order using underlying network/service platforms. During execution, the activation domain may retrieve service specifications via TMF633 Service Catalog, and it updates operational reality via TMF638 Service Inventory, which represents the authoritative record of deployed service state.
A critical part of the lifecycle is feedback and reconciliation. Fulfillment results and service state updates flow back asynchronously to the COM to advance and complete order state:
activation status / fulfillment result (primary driver of order progression)
service state / reconciliation (authoritative deployed state used for alignment and correction)
The COM then updates TMF637 Product Inventory, keeping responsibilities separated: service inventory reflects deployed technical reality, while product inventory reflects customer-facing product/subscription state.
Note: Shopping Cart (TMF663) is omitted for simplicity in this diagram. It can be implemented inside the BFF (internal cart) or exposed as a separate TMF API depending on the channel strategy.
What’s next
The purpose of this publication is to establish the architecture and integration patterns without drowning in specification-level detail. In the next publications, I will describe the detailed flows and state transitions per step — including practical examples of request/response sequences, event-driven feedback, and data model mappings (qualification inputs, order decomposition outputs, inventory updates, and reconciliation logic).
API architecture remains one of the core foundations of modern system integration. In 2025–2026, APIs are no longer simply technical interfaces — they define how systems evolve, how teams collaborate, and how organizations expose capabilities internally and externally. A well-designed API becomes a stable boundary between systems, allowing change without creating unnecessary coupling. For integration architects, API design is less about syntax and more about creating clear contracts that support long-term maintainability.
REST design
REST design continues to be the dominant paradigm for many business integrations because of its simplicity and broad adoption. However, mature REST design goes beyond basic CRUD endpoints. Integration architects must think in terms of resource modeling, clear naming conventions, stateless interactions, predictable response structures, and proper use of HTTP semantics. Good REST design reduces ambiguity and makes APIs intuitive for both developers and automated systems. Consistency across APIs is often more valuable than theoretical purity.
API-first approach
An API-first approach means designing interfaces before implementing underlying services or integrations. This encourages clarity of requirements, improves collaboration between teams, and allows parallel development. In modern integration environments, API-first practices help organizations avoid tightly coupled solutions by establishing clear interaction models early. Documentation, contract definition, and interface review become part of the design process rather than an afterthought.
Versioning strategies
Change is inevitable, and versioning strategies are essential for managing evolution without breaking existing consumers. Integration architects must decide when to introduce new versions, how to communicate deprecation, and how long to support older interfaces. Versioning is not just a technical detail — it is a governance decision that affects operational stability and user trust. Pragmatic approaches often include backward-compatible changes where possible and clear lifecycle management for APIs.
Idempotency
Idempotency is a critical concept for reliable integrations, especially in distributed environments where retries and network failures are common. Designing endpoints so that repeated requests produce consistent results helps prevent data corruption and unexpected side effects. Integration architects should consider idempotency in operations like payments, order processing, and state transitions, where accidental duplication can have serious consequences. Proper use of identifiers, tokens, or request keys helps maintain safe retry behavior.
Error handling patterns
Clear and consistent error handling is essential for operability. APIs should communicate failures in predictable ways, using structured error responses that allow clients to understand what went wrong and how to react. This includes meaningful status codes, machine-readable error messages, and clear separation between validation errors, business rule violations, and system failures. Good error design improves debugging, monitoring, and overall reliability of integration workflows.
Contract-driven development
Contract-driven development focuses on defining and maintaining explicit API contracts that both providers and consumers rely on. Tools such as OpenAPI specifications help ensure shared understanding between teams and reduce ambiguity during implementation. By treating the contract as a primary artifact, integration architects can enable testing, automation, and governance around interface changes. This approach strengthens collaboration and helps prevent breaking changes from propagating across complex integration landscapes.
Sync vs Async integration
You must know when to use:
REST sync
async messaging
event-driven
latency vs consistency trade-offs
…more
Understanding when to use synchronous or asynchronous integration patterns is one of the most important skills for an integration architect. Modern system landscapes often combine multiple communication models, and choosing the wrong one can lead to unnecessary complexity, performance bottlenecks, or fragile dependencies between systems. Rather than following trends, architects must evaluate business requirements, operational constraints, and system characteristics to determine the appropriate approach.
REST synchronous integration
Synchronous integrations, typically implemented through REST APIs, are well suited for scenarios where immediate responses are required and workflows depend on direct feedback. Examples include user-facing operations, validation checks, or transactional processes where a client needs a result before continuing. The advantages of synchronous communication include simplicity, clear request-response semantics, and easier reasoning about flow execution. However, synchronous systems create tighter coupling and can introduce cascading failures if downstream services become slow or unavailable.
Asynchronous messaging
Asynchronous messaging introduces decoupling between systems by allowing producers and consumers to communicate through message brokers or queues. This pattern is useful when workloads must be processed independently of immediate user interaction or when reliability and resilience are more important than instant responses. Messaging allows systems to handle spikes in load, recover from temporary failures through retries, and evolve independently. Integration architects must consider delivery guarantees, retry strategies, and message design to ensure predictable behavior.
Event-driven integration
Event-driven architectures extend asynchronous messaging by focusing on the publication of events that represent state changes within a system. Instead of directly requesting actions, systems react to events emitted by others. This approach improves scalability and flexibility, especially in distributed environments, but also introduces complexity around event ordering, data consistency, and monitoring. Architects must ensure that event-driven designs are introduced for real decoupling needs rather than as a default architectural choice.
Latency vs consistency trade-offs
One of the central decisions in integration architecture is balancing latency and consistency. Synchronous integrations typically provide immediate consistency but may suffer from higher latency and tighter dependencies. Asynchronous and event-driven models often improve responsiveness and resilience but introduce eventual consistency, requiring careful design of data synchronization and error recovery mechanisms. Understanding these trade-offs allows architects to align integration patterns with business priorities, such as user experience, reliability, or scalability.
Combining patterns pragmatically
In practice, most integration landscapes use a hybrid approach combining synchronous APIs with asynchronous messaging and event-driven workflows. Integration architects should avoid rigid adherence to a single paradigm and instead focus on selecting the simplest model that satisfies requirements. A pragmatic architecture often begins with synchronous integration for clarity and introduces asynchronous mechanisms where operational needs — such as resilience, scalability, or decoupling — justify the additional complexity.
Integration patterns
API facade
anti-corruption layer
orchestration vs choreography
canonical model vs mapping
pub/sub vs queue
…more
Integration patterns provide a shared architectural language that helps integration architects design systems in a structured and predictable way. Rather than inventing new solutions for every project, experienced architects rely on proven patterns to address recurring challenges such as coupling, system evolution, data transformation, and communication coordination. Understanding when and why to apply these patterns is often more important than mastering any specific technology.
API facade
The API facade pattern introduces a simplified interface that sits in front of one or multiple underlying services or systems. Its primary purpose is to hide internal complexity and present a stable, consumer-friendly contract. This is especially useful when integrating legacy systems or multiple backend services that expose inconsistent interfaces. An API facade can aggregate responses, normalize data structures, enforce security policies, or provide version stability while internal systems evolve. For integration architects, this pattern helps decouple external consumers from internal implementation details.
Anti-corruption layer
An anti-corruption layer (ACL) protects one domain model from being tightly coupled to another, especially when integrating modern systems with legacy platforms. Instead of allowing external data structures or business logic to leak into internal systems, the ACL translates between models and enforces boundaries. This reduces the risk of long-term architectural degradation and helps maintain clean domain separation. Integration architects often apply this pattern when introducing new systems into existing environments, allowing gradual migration without forcing immediate changes across the entire landscape.
Orchestration vs choreography
Orchestration and choreography represent two different ways of coordinating interactions between services. Orchestration relies on a central component that controls the workflow and manages execution steps, making it easier to understand and monitor complex processes. Choreography, on the other hand, distributes coordination across multiple services that react to events independently. While choreography can improve scalability and decoupling, it may also increase complexity and reduce visibility into overall process flow. Integration architects must evaluate the domain complexity, operational requirements, and team maturity when choosing between these approaches.
Canonical model vs mapping
When multiple systems exchange data, architects must decide whether to introduce a canonical data model or rely on direct mappings between systems. A canonical model establishes a shared representation of core business entities, which can simplify integration in large environments but requires governance and discipline. Direct mapping strategies may be simpler for smaller integrations but can become difficult to maintain as the number of connections grows. The right choice depends on scale, organizational structure, and expected system evolution.
Pub/Sub vs queue
Messaging patterns also require architectural decisions between publish/subscribe (pub/sub) and queue-based communication. Queue patterns are typically used for task processing where a message is handled by a single consumer, ensuring controlled execution and workload distribution. Pub/sub patterns broadcast events to multiple subscribers, enabling reactive and loosely coupled system behavior. Integration architects must consider factors such as ordering, scalability, delivery guarantees, and consumer independence when selecting between these models. Often, both patterns coexist within the same integration architecture, each serving different purposes.
Identity basics
OAuth2 flows
OpenID Connect
service-to-service auth
API security patterns
…more
Identity and access management have become essential components of modern integration architecture. As systems grow more distributed and APIs are exposed across organizational boundaries, security can no longer be treated as an afterthought. Integration architects must understand identity fundamentals well enough to design secure communication patterns, enforce trust boundaries, and prevent unauthorized access without introducing unnecessary complexity.
OAuth2 flows
OAuth2 has become the standard framework for delegated authorization in API-driven environments. Rather than sharing credentials directly between systems, OAuth2 allows controlled access through tokens issued by an authorization server. Integration architects do not need to implement OAuth2 internals, but they must understand the common flows — such as authorization code, client credentials, and device flows — and know when each is appropriate. Choosing the correct flow affects user experience, security posture, and operational complexity.
OpenID Connect
OpenID Connect builds on OAuth2 by adding authentication capabilities, allowing systems to verify user identity in a standardized way. In integration scenarios, OpenID Connect often enables single sign-on (SSO), centralized identity providers, and secure user context propagation across services. Architects should understand concepts such as ID tokens, identity claims, and federation between identity providers, ensuring that authentication responsibilities remain centralized rather than duplicated across multiple systems.
Service-to-service authentication
As architectures evolve toward distributed systems and microservices, service-to-service authentication becomes increasingly important. Machine-to-machine communication typically relies on token-based authentication using client credentials or mutual TLS. Integration architects must ensure that services authenticate each other securely while maintaining automation-friendly workflows. Proper token lifecycle management, secure storage of secrets, and clearly defined trust relationships are critical to avoiding vulnerabilities.
API security patterns
Beyond identity protocols, API security involves a broader set of architectural considerations. These include enforcing least-privilege access, validating input data, protecting against abuse through rate limiting, and using API gateways or proxies to centralize policy enforcement. Architects should also consider zero-trust principles, where every request is verified regardless of network location. The goal is not to create overly complex security mechanisms but to establish consistent, maintainable patterns that reduce risk while supporting scalability.
Security as part of architecture
Modern integration architecture treats identity and security as integral design elements rather than implementation details. Early decisions about authentication methods, token propagation, and access control models influence system maintainability and future extensibility. By incorporating identity considerations from the beginning, integration architects can reduce friction between teams, simplify compliance requirements, and ensure that integrations remain secure as systems evolve.
2. MODERN ARCHITECTURE STACK
Reverse proxy / API gateway / API management
Understand differencies:
reverse proxy — traffic routing
API gateway — policy enforcement + aggregation
API management — governance
…more
Modern integration architectures frequently rely on intermediary layers that sit between clients and backend services. Reverse proxies, API gateways, and API management platforms are often mentioned together, but they serve different architectural purposes. A senior integration architect must understand not only what each component does, but also when introducing them adds real value — and when it simply increases complexity without clear benefit.
Reverse proxy — traffic routing and edge control
A reverse proxy primarily acts as an entry point that forwards incoming requests to backend services. Its responsibilities typically include traffic routing, load balancing, TLS termination, caching, and basic security controls. Reverse proxies help simplify infrastructure by hiding internal service structures and presenting a unified external endpoint. For many small or medium integrations, a well-configured reverse proxy can provide sufficient functionality without introducing heavier architectural layers. Understanding this simplicity is important, because not every integration requires a full API gateway solution.
API gateway — policy enforcement and aggregation
An API gateway builds on reverse proxy capabilities by adding application-level functionality. Beyond routing traffic, API gateways enforce authentication and authorization policies, apply rate limiting, manage request transformations, and aggregate responses from multiple services. They can also centralize cross-cutting concerns such as logging, monitoring, and request validation. Integration architects use API gateways when there is a need for consistent policy enforcement across multiple APIs or when external consumers require a unified interface that hides internal service complexity.
API management — governance and lifecycle control
API management platforms operate at a broader organizational level. While they may include gateway functionality, their main focus is governance: managing API lifecycle, documentation, versioning, access control, analytics, and developer onboarding. API management introduces structure around how APIs are published, consumed, and evolved over time. This becomes particularly important in enterprise environments or multi-team organizations where APIs are treated as products and require formal governance models.
Choosing the right layer
A key architectural skill is recognizing that these layers are not interchangeable. Reverse proxies address infrastructure-level needs, API gateways address runtime policy and integration concerns, and API management addresses organizational governance. Introducing all three without clear requirements can lead to unnecessary operational overhead. Integration architects must evaluate scale, security requirements, team structure, and long-term API strategy before selecting the appropriate approach.
Pragmatic adoption
In many real-world projects, architectures evolve incrementally. A system may begin with a reverse proxy for simplicity, introduce gateway features as APIs grow, and adopt API management later when governance needs arise. This pragmatic progression allows organizations to balance flexibility with operational maturity. The goal is not to deploy the most advanced tooling but to introduce the right level of control at the right time, ensuring that integrations remain manageable and aligned with business goals.
Event platforms
You should understand:
broker vs event streaming
ordering vs scalability
delivery guarantees
when RabbitMQ simpler than Kafka
…more
Event platforms play an increasingly important role in modern integration architecture, especially as organizations move toward distributed systems and asynchronous communication. However, adopting event-driven approaches requires careful architectural thinking rather than simply choosing a popular technology. Integration architects must understand the conceptual differences between messaging models, evaluate trade-offs, and select the simplest solution that meets the operational and business requirements.
Broker vs event streaming
Traditional message brokers and event streaming platforms solve different problems, even though they are often discussed together. Message brokers, such as RabbitMQ, focus on reliable delivery of tasks or messages between producers and consumers. They are typically well suited for workflow orchestration, background processing, and decoupling services through queues. Event streaming platforms, such as Kafka, emphasize durable event logs and high-throughput streaming, allowing multiple consumers to process historical and real-time data independently. Integration architects must recognize whether the use case is task-oriented communication or continuous event processing before selecting an approach.
Ordering vs scalability
One of the key trade-offs in event platforms is balancing message ordering with scalability. Strict ordering guarantees can simplify processing logic but may limit throughput and parallelization. Highly scalable systems often distribute events across partitions, which improves performance but introduces complexity in maintaining order. Architects need to evaluate whether business processes truly require global ordering or whether localized ordering within partitions is sufficient. Understanding this trade-off helps avoid overengineering solutions that introduce unnecessary constraints.
Delivery guarantees
Event platforms provide different delivery semantics, such as at-most-once, at-least-once, or exactly-once processing. Each comes with operational implications and complexity trade-offs. For example, at-least-once delivery is common and generally easier to implement but requires idempotent consumers to avoid duplicate processing. Exactly-once semantics can reduce duplication risks but may introduce additional complexity and performance overhead. Integration architects must align delivery guarantees with real business needs rather than defaulting to the most complex option.
When RabbitMQ is simpler than Kafka
A common architectural mistake is adopting highly scalable event streaming platforms when a simpler message broker would be more appropriate. RabbitMQ and similar brokers are often easier to operate, require less infrastructure expertise, and provide sufficient capabilities for many integration scenarios such as asynchronous workflows, background processing, or service decoupling. Kafka becomes valuable when handling high-throughput data streams, long-lived event histories, or complex data pipelines. Senior integration architects recognize that choosing the simplest viable solution often leads to better maintainability and lower operational risk.
Pragmatic event-driven design
Event-driven architecture should be introduced intentionally and incrementally. Not every integration benefits from event streaming, and overusing event patterns can make systems harder to understand and operate. A pragmatic approach starts with clear use cases — such as decoupling, scalability, or resilience — and evaluates whether asynchronous messaging or event streaming genuinely improves the architecture. By focusing on outcomes rather than tools, integration architects can design systems that are both robust and maintainable.
Microservices reality
bounded contexts
data ownership
distributed failure modes
why not everything should be microservices
…more
Microservices have become a widely adopted architectural approach, but real-world experience has shown that they introduce both opportunities and significant challenges. For integration architects, understanding the practical realities of microservices is more important than following trends. Successful architectures focus on clear system boundaries, operational simplicity, and organizational alignment rather than blindly decomposing systems into smaller services.
Bounded contexts
One of the most important principles behind microservices is the concept of bounded contexts. Services should be defined around clear business domains rather than technical layers or arbitrary functional splits. A bounded context establishes ownership over specific business capabilities and allows teams to evolve services independently without creating tight coupling. Integration architects must ensure that service boundaries reflect domain logic and organizational structure, as poorly defined boundaries often lead to excessive inter-service communication and increased complexity.
Data ownership
In a microservices architecture, each service typically owns its data and controls access to it through defined APIs or events. This principle helps avoid shared databases and hidden dependencies, enabling services to evolve independently. However, strict data ownership introduces new challenges such as data duplication, synchronization strategies, and eventual consistency. Integration architects must carefully design how data flows between services, ensuring that responsibilities remain clear while minimizing unnecessary data coupling.
Distributed failure modes
Unlike monolithic systems, microservices operate in distributed environments where network failures, latency issues, and partial outages are normal conditions rather than exceptions. Integration architects must anticipate these failure modes and design resilience into the system. This includes implementing timeouts, retries, circuit breakers, and fallback strategies, as well as ensuring that monitoring and observability provide visibility into cross-service interactions. Understanding distributed failure patterns is essential for preventing cascading failures that can impact entire platforms.
Why not everything should be microservices
Despite their popularity, microservices are not a universal solution. They introduce operational overhead, increase system complexity, and require mature deployment, monitoring, and organizational practices. For smaller systems or straightforward business domains, simpler architectures — such as modular monoliths or well-structured APIs — may provide better long-term maintainability. Senior integration architects understand that the goal is not to adopt microservices by default but to choose the architectural style that best fits the scale, team structure, and business needs.
Pragmatic architectural thinking
The most effective integration strategies treat microservices as one tool among many rather than as an architectural ideology. A pragmatic approach evaluates whether service decomposition genuinely improves scalability, team autonomy, or system evolution. Often, systems evolve gradually, starting with simpler architectures and introducing microservices where clear boundaries and operational maturity exist. This incremental mindset helps organizations avoid unnecessary complexity while still benefiting from distributed architectures when they provide real value.
Cloud integration patterns
serverless integration
managed messaging
identity integration
cloud storage events
…more
Cloud platforms have fundamentally changed how integrations are designed and operated. Instead of building and maintaining infrastructure-heavy integration layers, organizations increasingly rely on managed services that reduce operational overhead while improving scalability and resilience. For integration architects, the focus is not simply on using cloud technologies, but on understanding patterns that allow systems to evolve flexibly while maintaining clarity and control.
Serverless integration
Serverless architectures enable event-driven or API-based integrations without requiring dedicated infrastructure management. Functions triggered by HTTP requests, events, or scheduled processes allow teams to implement lightweight integration logic that scales automatically based on demand. Serverless integration can be especially useful for data transformation, workflow automation, or connecting external APIs. However, integration architects must also consider aspects such as execution limits, cold-start latency, and observability challenges to ensure that serverless solutions remain reliable in production environments.
Managed messaging
Cloud providers offer managed messaging services that simplify asynchronous communication between systems. These services provide built-in scalability, delivery guarantees, and operational monitoring without requiring teams to operate their own messaging infrastructure. Managed queues, topics, and event buses allow integration architects to decouple services while reducing maintenance complexity. The architectural challenge is deciding when managed messaging provides sufficient flexibility and when more specialized event platforms are necessary for advanced use cases.
Identity integration
Identity integration is a key component of cloud-based architectures. Cloud identity services allow centralized authentication, authorization, and user management across multiple applications and APIs. Integration architects must understand how identity providers interact with APIs through tokens, roles, and access policies, enabling secure service-to-service communication and user authentication flows. Proper identity integration reduces duplication of security logic across systems and helps organizations implement consistent access control models.
Cloud storage events
Modern cloud storage platforms often support event-driven triggers when files are created, modified, or deleted. These storage events can initiate workflows such as data processing pipelines, document validation, or automated synchronization between systems. By leveraging storage events, integration architects can design reactive architectures that eliminate manual polling and improve efficiency. However, careful design is required to handle retries, duplicate events, and consistency considerations when building workflows around storage triggers.
Designing cloud-native integrations
Cloud integration patterns emphasize composability — combining small, managed services into flexible workflows rather than building monolithic integration layers. Architects must balance the advantages of managed services with concerns about portability, vendor-specific features, and long-term maintainability. A pragmatic cloud-native approach focuses on using platform capabilities where they provide clear benefits while maintaining architectural clarity and avoiding unnecessary complexity.
3. OBSERVABILITY & OPERABILITY
Integration architect is thinking about operations:
structured logging
metrics vs logs vs traces
failure visibility
retry strategies
dead-letter queues
…more
A key shift in modern integration architecture is the recognition that building integrations is only part of the work — operating them reliably over time is equally important. Integration architects must design systems with operational realities in mind from the beginning. Observability and operability are not optional enhancements but core architectural concerns that determine how easily issues can be detected, diagnosed, and resolved in distributed environments.
Structured logging
Structured logging provides machine-readable logs that allow systems to be monitored and analyzed efficiently. Instead of unstructured text messages, structured logs include consistent fields such as timestamps, request identifiers, correlation IDs, and contextual metadata. This enables better filtering, searching, and aggregation across multiple services. Integration architects should encourage consistent logging standards across systems to simplify debugging and improve operational visibility, especially when workflows span multiple components.
Metrics vs logs vs traces
Understanding the differences between metrics, logs, and traces is essential for effective observability. Metrics provide high-level insights into system health and performance trends, such as latency or error rates. Logs capture detailed events and contextual information that help explain what happened during execution. Distributed traces connect multiple service calls into a single flow, showing how requests move through the system. Integration architects must ensure that these signals complement each other, providing both overview monitoring and deep diagnostic capabilities.
Failure visibility
In distributed integration environments, failures are inevitable. The goal is not to eliminate failures entirely but to make them visible and understandable. Clear error reporting, alerting mechanisms, and monitoring dashboards help teams identify issues before they escalate into larger incidents. Integration architects should design systems that expose meaningful operational signals rather than hiding errors behind silent retries or unclear responses. Visibility into failures enables faster response times and improves system resilience.
Retry strategies
Retries are a common mechanism for handling transient failures such as network issues or temporary service outages. However, poorly designed retry logic can create cascading problems, including duplicated operations or system overload. Architects must define retry policies carefully, considering exponential backoff, maximum retry limits, and idempotency requirements. Integrations should distinguish between temporary errors that can be retried safely and permanent failures that require alternative handling.
Dead-letter queues
Dead-letter queues (DLQs) provide a controlled mechanism for handling messages that cannot be processed successfully after retries. Instead of losing data or endlessly retrying failed messages, DLQs isolate problematic cases for later analysis and manual intervention. This approach improves system reliability and prevents operational bottlenecks. Integration architects should design workflows that include clear processes for monitoring and resolving dead-letter messages, ensuring that operational teams can respond effectively.
Operational mindset
Ultimately, observability and operability reflect a broader architectural mindset: integrations are living systems that must be monitored, maintained, and evolved over time. By incorporating operational considerations into design decisions — from logging standards to error handling strategies — integration architects enable organizations to operate integrations confidently and sustainably in complex environments.
4. DELIVERY MODEL
fixed-scope integration vs platform build
how to reduce integration complexity
incremental integration strategy
avoiding overengineering
…more
Integration architecture is not only about technical design — it also involves choosing the right delivery approach. The way integrations are planned, scoped, and implemented directly influences cost, timelines, maintainability, and long-term success. A senior integration architect must understand how to balance business expectations with technical reality, selecting delivery models that provide value without creating unnecessary complexity or long-term risk.
Fixed-scope integration vs platform build
One of the most important decisions is distinguishing between focused integrations and building a broader integration platform. Fixed-scope integrations typically involve connecting a limited number of systems to solve a clearly defined business problem. These projects benefit from well-defined scope, predictable timelines, and pragmatic architecture. In contrast, platform-building initiatives aim to create reusable infrastructure or standardized integration layers across an organization. While platforms can offer long-term benefits, they require higher investment, governance, and organizational maturity. Integration architects must carefully evaluate whether a problem truly requires a platform or whether a simpler targeted solution is more appropriate.
Reducing integration complexity
Complexity often emerges unintentionally when systems are connected without clear architectural boundaries. A key responsibility of the integration architect is to actively reduce complexity rather than adding layers of abstraction by default. This includes minimizing unnecessary intermediaries, avoiding excessive transformations, and selecting integration patterns that remain understandable over time. Simplicity improves maintainability, accelerates onboarding for new team members, and reduces operational risk.
Incremental integration strategy
Large integration initiatives are rarely successful when delivered as monolithic projects. Instead, incremental strategies allow organizations to deliver value step by step, validating assumptions and adjusting architecture as requirements evolve. Integration architects should encourage iterative delivery, starting with minimal viable integrations and gradually expanding capabilities. This approach reduces risk, enables faster feedback cycles, and prevents organizations from overcommitting to architectural decisions before they are fully validated.
Avoiding overengineering
A common challenge in integration projects is the temptation to introduce advanced technologies or complex patterns prematurely. Overengineering can result from adopting trends without clear justification or attempting to anticipate every possible future requirement. Senior integration architects prioritize pragmatic solutions that solve current problems while remaining adaptable to change. Introducing complexity only when it delivers measurable value helps maintain clarity and ensures that systems remain manageable for both development and operations teams.
Aligning architecture with business outcomes
Ultimately, the delivery model should align technical decisions with business objectives. Integration architects must consider factors such as team capabilities, operational maturity, budget constraints, and long-term ownership. By choosing delivery strategies that emphasize clarity, incremental progress, and practical outcomes, architects help organizations achieve reliable integrations without unnecessary overhead or prolonged project timelines.
5. ENTERPRISE THINKING
High-level understanding:
API governance
version lifecycle
domain boundaries
data contracts
…more
Enterprise integration architecture requires a broader perspective than individual system connections or isolated projects. As organizations grow, integrations must support multiple teams, evolving business processes, and long-term system evolution. Enterprise thinking involves understanding how architectural decisions scale across domains, how standards are maintained over time, and how systems remain manageable even as complexity increases. Integration architects operating at this level focus on creating clarity, consistency, and governance without introducing unnecessary bureaucracy.
API governance
API governance establishes guidelines and practices that ensure consistency and quality across an organization’s APIs. This includes naming conventions, security policies, documentation standards, lifecycle management, and review processes. Effective governance does not mean rigid control but rather providing guardrails that help teams build interoperable and maintainable interfaces. Integration architects must balance flexibility and standardization, enabling teams to innovate while preventing fragmentation or incompatible implementations that complicate long-term integration.
Version lifecycle
Managing API evolution is a critical enterprise concern. Over time, APIs change as business requirements evolve, new capabilities are introduced, or technical improvements are implemented. A clear version lifecycle defines how APIs are introduced, updated, deprecated, and eventually retired. Integration architects must design strategies that allow change without breaking existing consumers, such as backward compatibility, phased deprecation, and clear communication with stakeholders. Well-managed version lifecycles reduce operational disruption and build trust with internal and external API consumers.
Domain boundaries
Enterprise architectures often involve multiple domains representing different business capabilities. Defining clear domain boundaries helps reduce coupling between teams and systems by establishing ownership and responsibility for specific areas. Integration architects use domain-driven thinking to prevent uncontrolled data sharing or tightly intertwined workflows. Clear boundaries enable independent evolution of systems while maintaining consistent integration through well-defined interfaces.
Data contracts
Data contracts define the structure, semantics, and expectations of information exchanged between systems. In enterprise environments, shared understanding of data is essential to avoid misinterpretation and integration errors. Contracts help ensure that producers and consumers align on formats, validation rules, and lifecycle expectations. Integration architects promote the use of explicit data contracts to support automation, testing, and governance, enabling organizations to evolve systems without introducing hidden dependencies.
Long-term architectural perspective
Enterprise thinking ultimately emphasizes sustainability. Integration architects must consider how decisions made today will impact future system evolution, organizational scaling, and operational stability. Rather than optimizing for short-term solutions alone, enterprise architecture aims to create structures that remain adaptable over time. By applying governance thoughtfully, respecting domain boundaries, and managing API and data lifecycles carefully, integration architects help organizations maintain control over complex integration landscapes.
OVERKILL — where you should not deep dive
Not so important to know as subject matter expert in details:
being deep expert in Kubernetes internals
write operators
deep service mesh networking
low-level Kafka cluster tuning
multi-cloud expert
This is a platform engineer territory.
…more
One of the most important skills for a senior integration architect is knowing not only what to learn, but also what not to specialize in too deeply. Modern technology landscapes are vast, and attempting to become a deep expert in every infrastructure or platform detail is neither realistic nor necessary. Integration architecture focuses primarily on designing interactions between systems, defining boundaries, and making pragmatic decisions that reduce complexity. Understanding where to draw the line between architectural knowledge and platform engineering expertise is essential for maintaining focus and effectiveness.
Not every technical area requires deep specialization
Integration architects benefit from broad technical awareness across infrastructure, cloud platforms, and distributed systems. However, deep expertise in low-level implementation details is often the responsibility of specialized roles such as platform engineers, DevOps engineers, or site reliability engineers. The architect’s role is to understand capabilities, limitations, and trade-offs at a conceptual level rather than managing operational internals or optimizing infrastructure configurations.
Kubernetes internals and operator development
Kubernetes has become a common deployment platform, and integration architects should understand its high-level concepts — such as containers, scaling, service discovery, and deployment patterns. However, deep knowledge of Kubernetes internals, custom resource definitions, or writing operators is typically unnecessary unless the role directly involves platform engineering. Architects should focus on how integrations behave within containerized environments rather than mastering cluster-level mechanics.
Deep service mesh networking
Service meshes introduce advanced capabilities such as traffic management, resilience policies, and observability across microservices. While architects should understand the purpose and implications of service mesh adoption, deep expertise in networking internals, sidecar configuration, or low-level performance tuning is generally beyond the scope of integration architecture. The primary concern is evaluating whether a service mesh solves real architectural problems, not becoming a specialist in its internal mechanics.
Low-level Kafka cluster tuning
Event streaming platforms like Kafka can require significant operational expertise, including cluster management, partition balancing, and performance optimization. Integration architects should understand event-driven design patterns and messaging trade-offs but do not need to specialize in infrastructure-level tuning. These responsibilities are better handled by platform teams responsible for maintaining reliable infrastructure.
Multi-cloud expertise as infrastructure specialization
While architects may design integrations that span multiple cloud providers, becoming a deep multi-cloud infrastructure expert is rarely necessary. Integration architects should focus on cloud integration patterns, identity integration, and service capabilities rather than mastering every provider’s low-level services or operational tooling. Broad understanding enables informed architectural decisions without diverting attention away from integration strategy.
Staying focused on architectural value
Avoiding over-specialization allows integration architects to concentrate on their primary value: making clear architectural decisions that simplify system interaction and support long-term evolution. By maintaining high-level awareness without diving too deeply into platform engineering domains, architects can collaborate effectively with specialized teams while preserving a holistic view of the integration landscape.
Mental model of integration architect
You are not a tool specialist, but a decision maker who reduces complexity.
…more
The core mindset of a modern integration architect is fundamentally different from that of a tool specialist or technology evangelist. While tools and platforms are important, they are not the primary focus. The real value of an integration architect lies in making informed decisions that reduce complexity, improve clarity, and enable systems to evolve sustainably over time. In 2025–2026, successful integration work is less about mastering specific products and more about understanding patterns, trade-offs, and organizational realities.
From tool selection to decision-making
Many technical roles emphasize expertise in particular frameworks or platforms. Integration architecture, however, requires a broader perspective. Tools change quickly, but architectural principles remain relatively stable. The architect’s responsibility is to evaluate whether a specific technology genuinely solves a problem or simply adds another layer of abstraction. This means asking questions about long-term maintainability, operational impact, team capabilities, and business outcomes rather than focusing solely on technical features.
Reducing complexity instead of adding it
Integration projects often become complicated because multiple systems, teams, and requirements intersect. Without careful design, integrations can accumulate unnecessary layers, inconsistent data models, and fragile dependencies. A key skill of an integration architect is recognizing when complexity is unavoidable and when it is self-inflicted. By simplifying interfaces, choosing clear patterns, and avoiding premature optimization, architects help organizations maintain systems that remain understandable and maintainable over time.
Thinking in trade-offs
Architectural decisions rarely have perfect solutions. Every choice introduces trade-offs between flexibility, performance, cost, scalability, and operational effort. The integration architect’s mental model focuses on understanding these trade-offs and selecting options that align with the organization’s priorities. For example, choosing synchronous APIs may simplify implementation but reduce resilience, while event-driven architectures increase flexibility but add operational complexity. The role involves balancing these considerations rather than pursuing idealized designs.
Aligning technology with business context
Integration architecture exists at the intersection of technology and business needs. Decisions about APIs, messaging, or system boundaries should reflect organizational structure, delivery speed, and operational maturity. A solution that works well in a large enterprise environment may be unnecessarily complex for a smaller team. By aligning architecture with context, integration architects ensure that systems remain practical and sustainable rather than overly ambitious or under-engineered.
Collaboration and shared understanding
Reducing complexity also involves improving communication between teams. Integration architects help establish shared language through patterns, contracts, and consistent design principles. This reduces misunderstandings and enables teams to work independently while maintaining interoperability. The architect’s role is not only technical but also facilitative, helping teams align around clear integration strategies.
Architecture as continuous evolution
Finally, the mental model of an integration architect recognizes that architecture is not a one-time decision but an ongoing process. Systems evolve, requirements change, and new technologies emerge. By focusing on simplicity, adaptability, and clear boundaries, integration architects create environments where change can occur without constant rework. The ultimate goal is not to build the most advanced system, but to create one that remains manageable and adaptable as the organization grows.