Pragmatic Patterns Using TMF641, TMF633, and TMF638
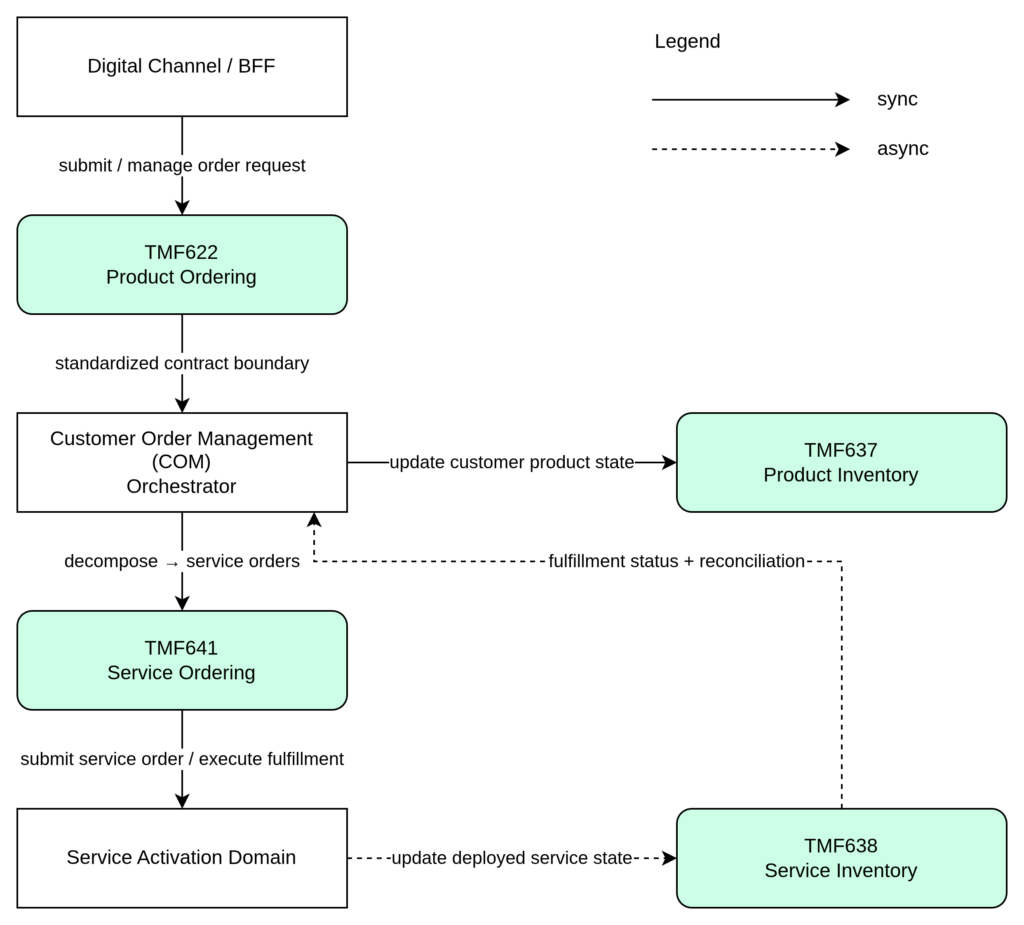
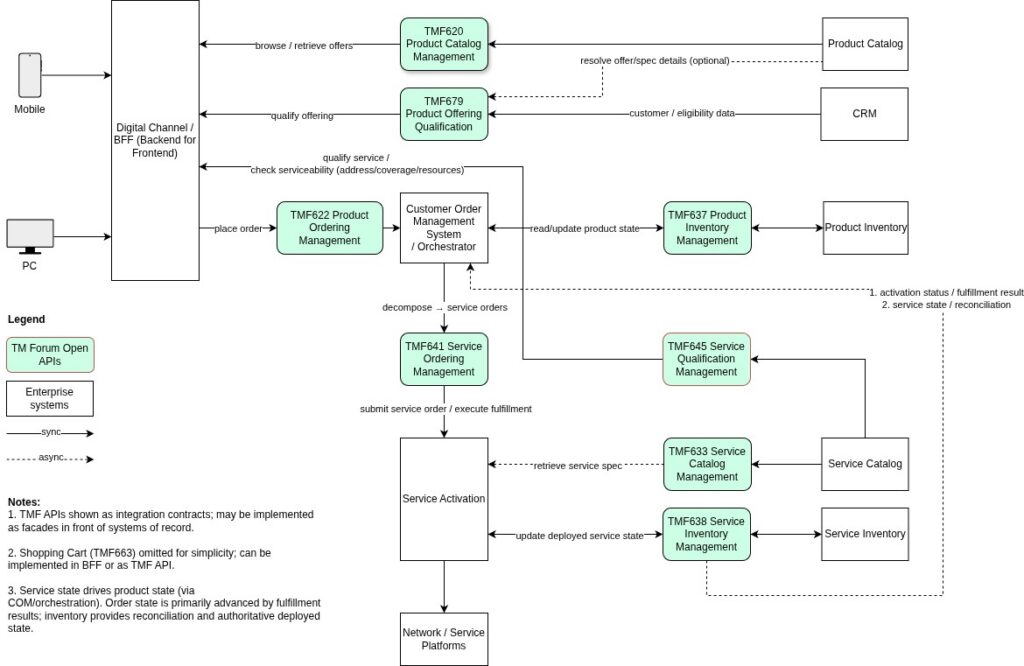
In the previous articles, we examined how customer intent is captured and standardized through TMF622 Product Ordering, and how Customer Order Management decomposes product orders and orchestrates lifecycle progression. Now we move to the final and often most complex domain: Service Activation and Operational State Management.
This domain represents the transition from commercial abstraction to technical execution — where real infrastructure constraints, asynchronous processes, and operational reality must be handled pragmatically. This article demonstrates how TMF641 Service Ordering, TMF633 Service Catalog, and TMF638 Service Inventory can be applied without introducing unnecessary orchestration complexity or tightly coupled fulfillment architectures.
The Service Activation Domain
The Service Activation domain operates under fundamentally different conditions than commercial order management. Where product ordering captures commercial intent, service activation is responsible for executing that intent within the operational environment. It translates service orders into concrete technical actions across network platforms, infrastructure components, and operational support systems.
Typical responsibilities within this domain include:
| Responsibility | Description |
| Network provisioning | Configuring network elements, access technologies, or connectivity services |
| Resource configuration | Allocating and binding technical resources required for service delivery |
| Platform activation | Enabling services on application or service platforms (e.g., IPTV, VoIP, mobile) |
| OSS integration | Interacting with provisioning systems, resource managers, and inventory platforms |
| External vendor integration | Invoking third-party or partner systems required for service delivery |
Operational characteristics in this domain differ significantly from upstream commercial systems. Service activation processes are typically:
- Long-running — execution may span minutes, hours, or longer depending on infrastructure dependencies
- Asynchronous — progress and results are delivered through events or status updates, not immediate responses
- Failure-prone — network conditions, resource constraints, and external dependencies introduce frequent failure scenarios
- Partially executable — complex services may activate some components successfully while others require retries or remediation
| Architectural Implication Because of these characteristics, the Service Activation domain must be designed to handle asynchronous execution, tolerate partial outcomes, and provide clear operational feedback to upstream order management systems. Architectures that assume synchronous, always-successful activation will fail at operational scale. |
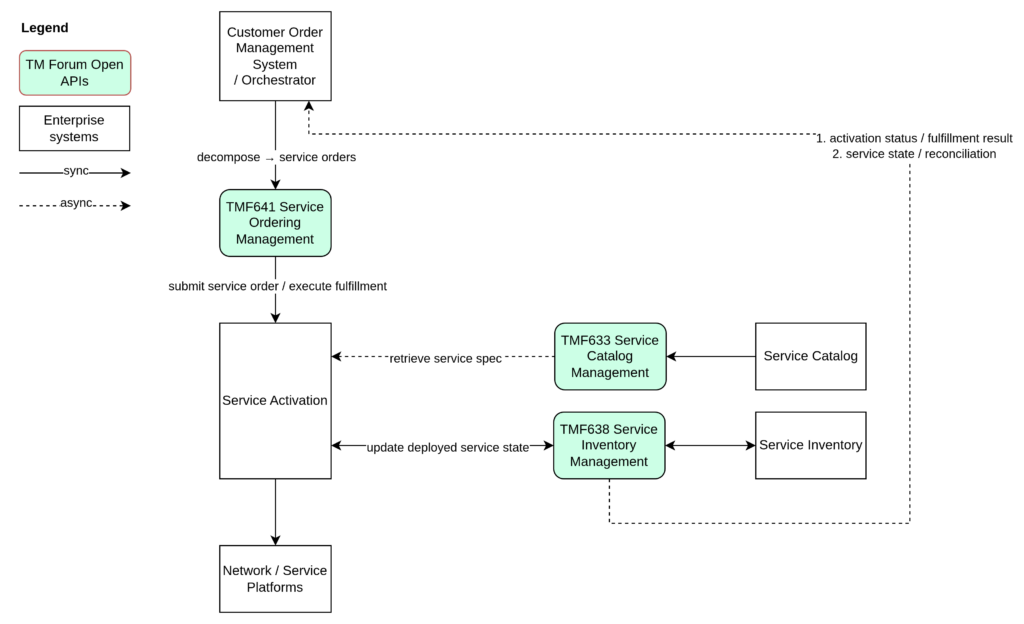
Service Ordering — TMF641
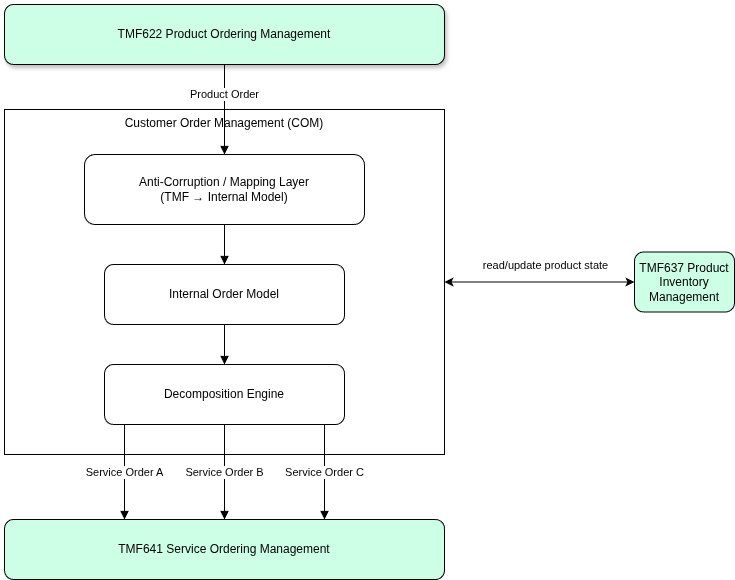
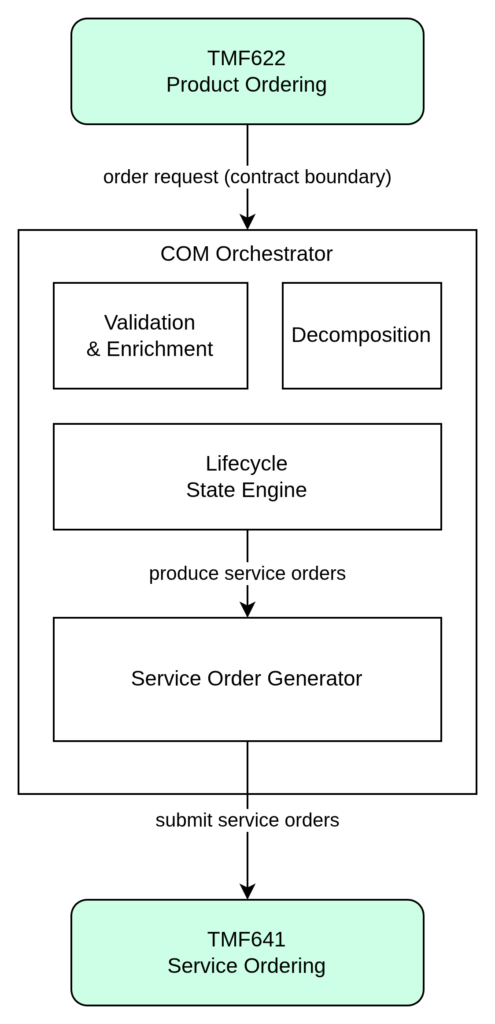
TMF641 Service Ordering Management API acts as the operational boundary between order orchestration and service execution. When Customer Order Management completes product order decomposition, the resulting service-level work requests are submitted through TMF641. At this point, responsibility shifts from commercial orchestration to technical fulfillment.
TMF641 therefore provides a stable execution interface that allows the orchestration layer to trigger service delivery while remaining independent from the internal design of activation systems.
What TMF641 Is — and Is Not
| TMF641 IS… | TMF641 is NOT… |
| A contract for requesting service execution | A workflow engine |
| A lifecycle state tracking interface | A process definition framework |
| An operational boundary between domains | A platform for implementing provisioning logic |
| A stable integration surface for orchestrators | An internal activation system |
Through this contract, the orchestrator can reliably initiate fulfillment activities without needing to understand how those activities are implemented internally. The key architectural rule is:
| TMF641 enables execution requests — it does not define execution logic. |
Separation of Responsibilities: Orchestration vs. Fulfillment
A clean architecture requires a clear distinction between order orchestration decisions and service activation execution. The two domains have fundamentally different roles:
| Customer Order Management (COM) | Service Activation Domain |
| Interprets the incoming TMF622 ProductOrder | Determines how provisioning must be performed |
| Decomposes the order into service-level actions | Identifies which OSS systems or network controllers to invoke |
| Submits ServiceOrders through TMF641 | Manages dependencies between provisioning steps |
| Monitors fulfillment progress and advances product order state | Handles technical failures, retries, and recovery |
In simple terms: COM decides what must be delivered. Service Activation decides how it is delivered.
Maintaining this separation prevents a common and costly anti-pattern: embedding provisioning logic inside the orchestration domain. When orchestration layers begin implementing detailed activation workflows, they become tightly coupled to network implementation details, making the system difficult to evolve and scale.
By keeping execution logic inside the fulfillment domain and using TMF641 purely as an execution contract, the architecture remains modular, maintainable, and resilient as both commercial and operational systems evolve independently.
Service Catalog — TMF633
TMF633 Service Catalog Management API provides the technical definitions of services required by fulfillment and activation domains. While product catalogs describe commercial offerings, the service catalog defines how those offerings are realized at the technical level.
The Service Catalog typically contains:
- Service specifications describing the structure and characteristics of technical services
- Resource requirements indicating dependencies on network or platform resources
- Configuration templates used during provisioning and activation
- Activation metadata that guides provisioning systems on how services should be instantiated
Activation and fulfillment systems may use TMF633 to resolve service specification details, validate technical configuration constraints, and retrieve provisioning parameters referenced in service orders.
Design-Time Reference, Not Runtime Dependency
From an architectural perspective, the Service Catalog should be treated as a supporting design-time and reference domain — not a synchronous runtime dependency on every activation request.
| Recommended Approach Cache required catalog metadata within fulfillment systems at startup or on demand. Apply explicit versioning of service specifications to ensure predictable execution across releases. Avoid synchronous catalog lookups on critical provisioning paths — catalog unavailability must never block service activation. |
This approach maintains activation performance, resilience, and operational stability, while ensuring that fulfillment systems rely on consistent and governed service definitions.
Execution Model — Asynchronous by Design
Service activation processes are inherently asynchronous and long-running. Unlike commercial order submission, technical provisioning typically involves multiple downstream systems, infrastructure platforms, and external integrations that cannot complete within a single synchronous request.
Typical Execution Lifecycle
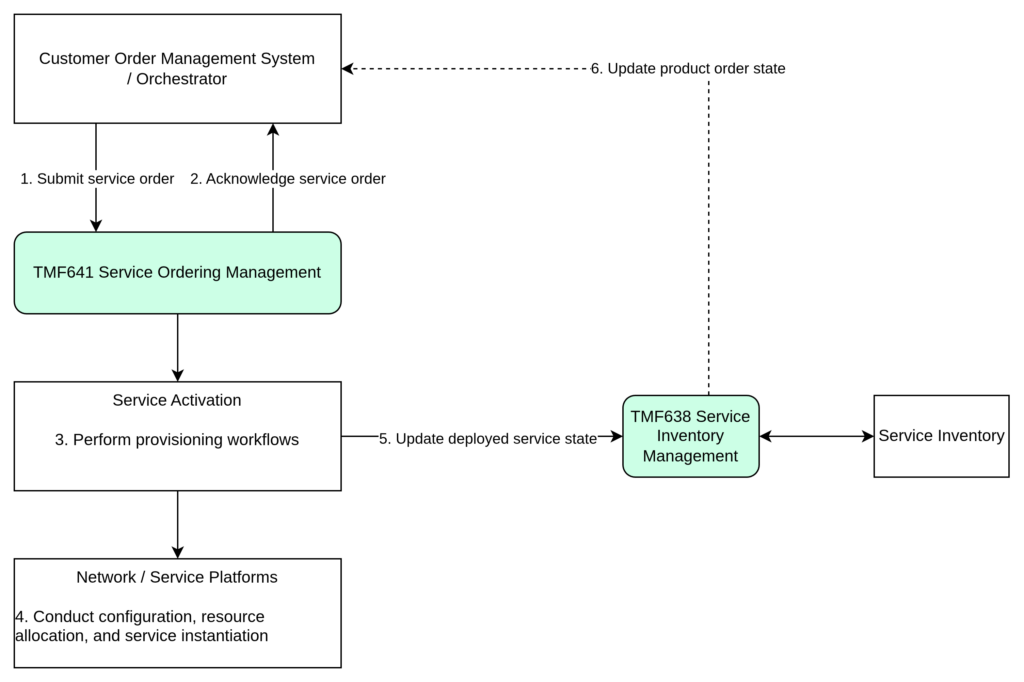
| Step | Actor | Action |
| 1 | COM | Submits ServiceOrder via TMF641 |
| 2 | Activation Domain | Accepts and acknowledges the ServiceOrder |
| 3 | Activation Domain | Initiates internal provisioning workflows |
| 4 | Underlying Systems | Perform configuration, resource allocation, and service instantiation |
| 5 | Activation Domain | Emits lifecycle status updates as execution progresses |
| 6 | COM | Processes status events and advances product order state |
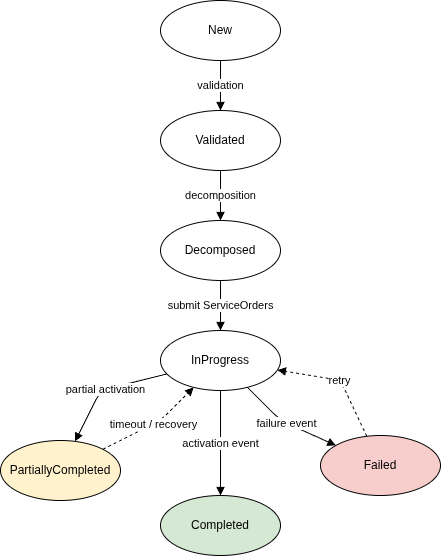
Lifecycle States
During execution, the activation domain reports the following intermediate lifecycle states:
| State | Meaning | COM Response |
| acknowledged | Request accepted for processing | Record confirmation; no state change |
| inProgress | Provisioning activities are executing | Maintain InProgress order state |
| pendingExternal | Waiting on an external system or vendor | Apply timeout monitoring; prepare retry |
| completed | Service successfully activated | Advance order to Completed; update TMF637 |
| failed | Provisioning could not be completed | Enter recovery logic; evaluate retry or rollback |
| Design Principle Orchestration and order management domains must rely on event-driven feedback and lifecycle state transitions — not on synchronous completion of activation requests. A completed API call means the request was accepted. It does not mean the service was activated. |
Service Inventory — TMF638
A fundamental architectural principle of fulfillment architecture is: the authoritative deployed state of services must be maintained in Service Inventory.
TMF638 Service Inventory represents the actual technical deployment of services in the network and platforms. It reflects what is really running in the infrastructure, independent of commercial intent or ordering processes.
TMF638 typically stores:
- Deployed service instances and their identifiers
- Active configurations and binding parameters
- Relationships between services and underlying resources
- Operational lifecycle state of each service (active, suspended, terminated, degraded)
| Key Principle Service Inventory is not a tracking repository for orders. It is the source of truth for operational reality within the OSS landscape. Other domains — assurance, monitoring, reconciliation — must rely on TMF638, not on order state, to understand what is actually deployed. |
During service activation, provisioning systems interact with infrastructure components and progressively update Service Inventory as deployment evolves — creating new service instances, modifying configuration, and recording operational state changes.
Feedback to the Order Domain
Once service activation begins, Customer Order Management must rely on asynchronous feedback from fulfillment and inventory domains to understand how execution is progressing. Two primary categories of signals flow back to the order domain.
1. Fulfillment Results
Fulfillment systems provide execution outcomes for service orders, typically through TMF641 interfaces. These signals drive the lifecycle of the commercial order managed through TMF622 and are used to:
- Advance the order state machine
- Confirm successful activation
- Report execution failures for recovery handling
- Identify partial completion scenarios requiring intervention
2. Operational State Updates
A second category of signals originates from the operational environment — specifically, the service inventory maintained through TMF638. These updates represent the actual technical state of deployed services, independent of the order workflow.
Operational state signals are used for:
- Inventory reconciliation and drift detection
- Identifying service degradation or configuration inconsistencies
- Triggering corrective actions in assurance or orchestration systems
| Example Scenario A ProductOrder has been marked Completed in the order domain. Later, TMF638 Service Inventory reports that the corresponding service instance has entered a degraded operational state. In this situation: COM may initiate corrective workflows, assurance systems may trigger incident handling, and orchestration may request re-provisioning. Order completion does not guarantee long-term operational correctness. Robust architectures must maintain continuous feedback loops between fulfillment, inventory, and order management. |
Handling Reality Drift
In operational environments, reality drift occurs when the actual deployed state of a service diverges from the expected state defined during order fulfillment. This divergence is common in large distributed telecom environments and must be explicitly addressed in system design.
Common Causes
| Cause | Description |
| Manual network changes | Configuration changes applied outside automated workflows, bypassing inventory updates |
| Vendor inconsistencies | Delayed or incomplete responses from partner or third-party APIs |
| Partial provisioning failures | Some service components activate successfully while others fail silently |
| Out-of-band interventions | Operational changes applied during incident resolution without proper lifecycle tracking |
Architectural Patterns for Managing Drift
1. Periodic Reconciliation
Scheduled reconciliation jobs compare the deployed service state stored in TMF638 with the real configuration observed in network or platform systems. These processes identify discrepancies and trigger corrective actions when necessary. Reconciliation frequency should be calibrated to the operational risk tolerance of the service type.
2. Event-Driven Inventory Updates
Modern architectures increasingly rely on event-driven mechanisms where network platforms emit state change events that update Service Inventory in near real time. This approach significantly reduces the window during which inconsistencies can exist undetected, and eliminates the latency inherent in scheduled reconciliation.
3. Domain-Specific Repair Workflows
When inconsistencies are detected — whether through reconciliation or event-driven signals — specialized repair workflows are triggered within the activation domain. These workflows may:
- Reapply configuration to bring the network element back to the expected state
- Restore missing or corrupted service components
- Synchronize service state across all affected inventory and assurance systems
- Escalate to manual intervention when automated repair is not viable
Avoiding Fulfillment Complexity Traps
Service activation architectures accumulate complexity over time — often through well-intentioned design decisions that solve short-term problems while creating long-term constraints. The following anti-patterns appear repeatedly in telecom BSS/OSS implementations and are worth addressing explicitly.
1. The Centralized Mega-Orchestrator
As activation requirements grow, there is a recurring temptation to introduce a single orchestration platform that owns the end-to-end fulfillment workflow — from ServiceOrder receipt through network provisioning, resource allocation, and inventory update. This approach typically starts as a pragmatic shortcut and gradually accumulates ownership of everything.
The consequences are predictable:
- A single point of failure that affects all service types simultaneously
- Deployment bottlenecks — every change to any service requires a release of the central platform
- Performance degradation as order volumes grow and all execution serializes through one engine
- Deep coupling between commercial product models and network implementation details
| Preferred Approach Prefer domain-specific execution logic. Each service type or service family should own its activation workflow. Use TMF641 as the stable interface through which these domain-specific activators are invoked. Orchestration coordinates — it does not implement provisioning steps. |
2. Overusing Workflow Engines
Visual workflow engines (BPM platforms, low-code orchestration tools) are valuable for genuinely complex, human-in-the-loop, or highly variable processes. However, many telecom provisioning flows are deterministic, rule-based, and predictable. Modeling these flows in a heavyweight workflow engine introduces operational overhead without architectural benefit.
Signs that a workflow engine is being overused:
- Simple sequential activation steps modeled as multi-node workflows with branching logic
- The workflow engine becomes the only way to understand what the system does
- Changes to provisioning logic require workflow designer involvement rather than code review
| Preferred Approach Use state-machine-based execution for deterministic provisioning flows. Reserve workflow engines for processes that are genuinely variable, approval-dependent, or require human intervention. Explicit state machines are easier to test, version, and reason about than visual workflow definitions. |
3. Synchronous Activation Chains
A synchronous activation chain occurs when each provisioning step waits for the previous one to complete before proceeding — creating a long, blocking call chain that spans multiple systems. This pattern is fragile: a single slow or unavailable system causes the entire chain to stall or time out.
Common manifestations include:
- Direct synchronous calls from the orchestrator into multiple downstream provisioning systems in sequence
- Timeout values set high to accommodate slow external systems, masking latency problems
- Error handling that propagates exceptions upward through the call chain rather than isolating failures
| Preferred Approach Design activation flows as asynchronous command-and-event sequences. Each provisioning step emits a completion event. The next step is triggered by that event, not by a return value. This decouples execution timing, isolates failures, and allows individual steps to retry independently without affecting the rest of the workflow. |
Integration Pattern Summary
When the Service Activation domain is implemented correctly, it becomes a well-bounded, operationally stable execution layer that supports both commercial agility and technical evolution. The following summarizes the key responsibilities and their rationale.
| Responsibility | Mechanism | Rationale |
| Execute ServiceOrders | TMF641 Service Ordering API | Provides a stable, domain-independent execution contract |
| Resolve technical definitions | TMF633 Service Catalog (cached) | Decouples activation from catalog availability at runtime |
| Maintain authoritative deployed state | TMF638 Service Inventory | Ensures operational truth is available to all consuming domains |
| Emit lifecycle updates | Asynchronous events / callbacks | Allows orchestration to progress without blocking on activation |
| Decouple from commercial models | Anti-Corruption Layer at domain boundary | Allows product and service domains to evolve independently |
| Handle failures locally | Domain-specific retry and repair workflows | Prevents failure propagation into orchestration and order domains |
When implemented correctly:
- Operational complexity is isolated within the activation domain and does not leak into orchestration
- The orchestration layer remains clean, focused on lifecycle coordination rather than provisioning detail
- Individual activation domains can be scaled, replaced, or evolved without impacting upstream systems
- TMF APIs serve as integration boundaries — not as architectural foundations for internal design
Closing the Lifecycle
This article concludes the three-part series on TM Forum Open API architecture. Across the trilogy, three distinct domains work in sequence to translate a customer’s commercial intent into a delivered, operational service.
| Domain | Primary APIs | Core Responsibility |
| Customer Order Capture | TMF622 Product Ordering | Validates and standardizes commercial intent into a structured ProductOrder |
| Customer Order Management | TMF622, TMF641, TMF637 | Decomposes the ProductOrder, orchestrates lifecycle, and coordinates fulfillment feedback |
| Service Activation & Inventory | TMF641, TMF633, TMF638 | Executes technical provisioning and maintains authoritative operational state |
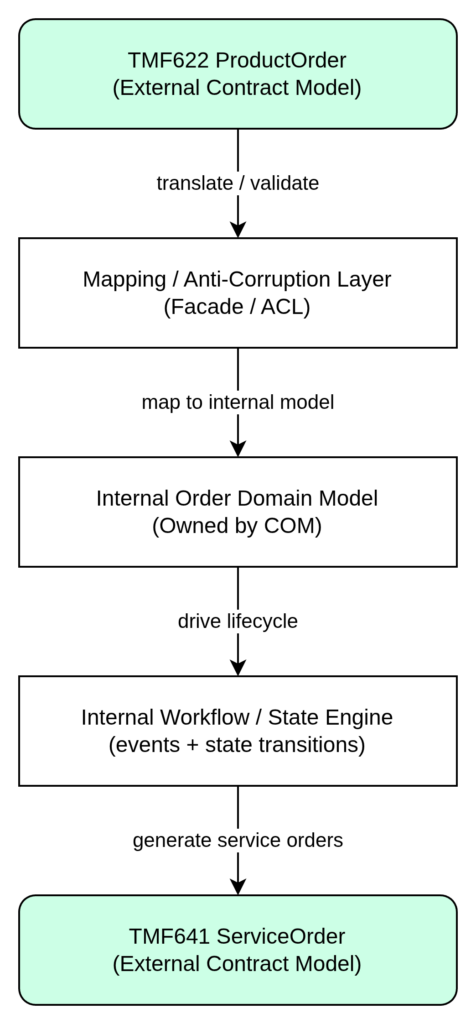
TM Forum Open APIs serve a specific and bounded purpose in this architecture: they define domain boundaries, provide integration contracts, and establish interoperability standards between systems. They define the shape of the interface between domains — not the internal behavior of those domains.
| A Closing Principle TMF APIs should never dictate internal architecture. A system that models its internal domain logic directly on TMF JSON structures will be brittle, difficult to evolve, and tightly coupled to API version cycles. Use TMF APIs at the boundary. Use domain models internally. The Anti-Corruption Layer is not optional — it is the mechanism that keeps these concerns separate. |
Across all three domains, the architectural thread is consistent: own your domain logic, expose clean contracts, and use standard APIs as integration surfaces — not as blueprints for internal design. That separation is what makes telecom BSS/OSS architectures scalable, maintainable, and capable of evolving with both business and technology change.
Implementation Approaches: Platforms vs. Tailor-Made Development
Service Activation architectures can be implemented in several ways, each with distinct trade-offs in cost, flexibility, time-to-market, and long-term maintainability. The right choice depends on the operator’s scale, existing technology landscape, team capabilities, and the degree of domain specificity required.
Option 1 — Vendor Platforms
Established commercial platforms such as Nokia NSP, Ericsson OSS/BSS, IBM Sterling Order Management, and Netcracker provide pre-built fulfillment engines with native TMF API support, lifecycle management, and operational tooling. These solutions reduce time-to-market and bring proven operational patterns validated across large deployments.
Trade-offs to consider:
- High upfront licensing and integration cost
- Customisation of domain-specific business rules is constrained by the platform model
- Vendor lock-in can limit architecture evolution and renegotiation leverage
Option 2 — Open-Source Platforms
Frameworks such as ONAP (Open Network Automation Platform) and OSM (Open Source MANO) provide community-driven orchestration and fulfillment capabilities with TMF alignment. These platforms are particularly relevant for operators pursuing open ecosystem strategies or needing multi-vendor network automation.
Trade-offs to consider:
- Lower licensing cost, but significant investment in integration, configuration, and support
- Community-driven TMF alignment varies in completeness across modules
- Operational maturity depends heavily on internal DevOps and OSS expertise
Option 3 — Composable Frameworks
A growing number of teams adopt a composable approach: using a lightweight orchestration framework such as Temporal, Conductor, or Camunda for workflow coordination, while keeping domain-specific activation logic in purpose-built microservices that expose TMF641-compliant interfaces. This model offers high flexibility without building everything from scratch.
Trade-offs to consider:
- Requires strong distributed systems expertise to operate reliably at scale
- TMF alignment is manual — the team owns the integration contract design
- Well-suited to organizations with mature engineering practices and evolving product portfolios
Option 4 — Tailor-Made Development
Full custom development — typically using runtimes such as Spring Boot, Quarkus, or Node.js combined with event streaming platforms like Apache Kafka or RabbitMQ — gives teams complete control over domain logic, state machine design, and integration contracts. This approach is justified when the domain logic is genuinely unique and no existing platform models it adequately.
Trade-offs to consider:
- Highest initial investment in design, development, and operational tooling
- Long-term maintenance ownership rests entirely with the internal team
- Full alignment with domain model and TMF contracts — no platform constraints
Option 5 — Hybrid Approach
In brownfield environments, a hybrid strategy is often the most pragmatic path: retaining existing vendor platforms for stable, high-volume service types while introducing composable or tailor-made components for new services, digital channels, or domains requiring faster evolution. This allows incremental modernization without a full platform replacement.
Decision Matrix
The following matrix summarizes the key dimensions across all five approaches to support architectural decision-making:
| Criterion | Vendor Platform | Open-Source Platform | Composable Framework | Tailor-Made | Hybrid |
| Time to market | Fast | Medium | Medium | Slow | Medium |
| Upfront cost | High | Low–Medium | Low–Medium | High | Medium–High |
| Vendor lock-in | High | Low | Low | None | Partial |
| TMF alignment | Native/partial | Community-driven | Manual | Full control | Mixed |
| Customisation | Limited | Moderate | High | Full | High |
| Operational maturity | High | Medium | Medium | Low initially | Medium–High |
| Team skill demand | Platform-specific | DevOps + OSS | Distributed systems | Strong dev team | Mixed |
| Best fit | Large operators,fast rollout | Cost-sensitive, open ecosystem | Flexible orchestration needs | Unique domain logic | Brownfield + evolution |
| A Constant Across All Approaches Regardless of the implementation path chosen, the architectural principles remain the same. TMF APIs define the boundaries. Domain logic stays internal. Operational state is always owned by Service Inventory. The platform or framework is an implementation detail — the domain model is the architecture. |